Python
Python RPA(업무자동화) 개념 및 실습 - 크롤링(정규표현식)(1)
developers developing
2022. 10. 1. 12:00
정규 표현식
- 특정한 패턴과 일치하는 문자열을 검색, 치환, 제거하는 기능
파이썬 정규표현식 생성 - re모듈
- 메소드
- match() : 문자열 처음부터 정규식과 매칭되는 패턴 찾아서 리턴
- search() : 문자열 전체를 검색해서 정규식과 매칭되는 패턴 찾아서 리턴
- findall() : 정규식과 일치하는 모든 문자열을 찾아 리스트로 반환
- finditer() : 정규식과 일치하는 모든 문자열을 찾아 iterator 객체로 반환
- split() : 정규식을 기준으로 문자열 분리 후 리스트로 반환
- re.sub(패턴, 바꿀문자열, 원본문자열) : 찾아서 바꾸기
- 패턴 [ ] : [ ] 안에 있는 일치하는 문자가 있으면 매치한다
- Dot(.) : 모든 문자를 의미
- ? : 최소 0 ~ 최대 1 반복
- 반복(*) : 바로 앞에 있는 문자가 반복 횟수가 0~무한대로 반복
- 반복(+) : 바로 앞에 있는 문자가 반복 횟수가 1~무한대로 반복
- {n} : n만큼 반복
- {n,m} : 최소 n, 최대 m 반복
- [ - ] : 사이의 범위를 의미
- [ ^ ] : 포함하지 않음
RPAbasic\regex 폴더 - regex1.py
import re
# 패턴 생성
pattern = re.compile("D.A") # 가지고 있는 문자열에 "D.A"이 있는지 찾고 싶음
# 패턴 매칭 여부 확인
result = pattern.search("DAA")
print(result)
# 돌아오는 형태는 Match 형태
print("패턴 시작 위치", result.start()) # 시작 위치
print("패턴 끝 위치", result.end())
print("패턴과 일치하는 문자열", result.group())
print("패턴과 일치하는 위치", result.span()) # 튜플로 묶어서 받을 수 있음
result = pattern.search("D1A")
print(result)
result = pattern.search("D00A")
print(result) # 매칭 되지 않으면 None으로 돌아옴
print()
result = pattern.search("d0A D2A 0111")
print(result)
print()
# re.compile() 사용하지 않고 간단하게 만들기
print(re.search(r"D.A", "DAA")) # 패턴이 없기 때문에 re를 사용
print(re.search(r"D.A", "D1A"))
print(re.search(r"D.A", "D00A"))

RPAbasic\regex 폴더 - regex2.py
import re
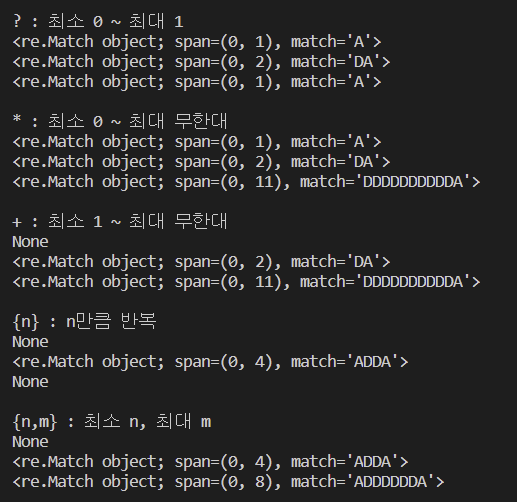
pattern = re.compile("D?A")
print("? : 최소 0 ~ 최대 1")
print(pattern.search("A"))
print(pattern.search("DA"))
print(pattern.search("AA"))
pattern = re.compile("D*A")
print("* : 최소 0 ~ 최대 무한대")
print(pattern.search("A"))
print(pattern.search("DA"))
print(pattern.search("DDDDDDDDDDA"))
pattern = re.compile("D+A")
print("+ : 최소 1 ~ 최대 무한대")
print(pattern.search("A")) # None
print(pattern.search("DA"))
print(pattern.search("DDDDDDDDDDA"))
print()
pattern = re.compile("AD{2}A")
print("{n} : n만큼 반복")
print(pattern.search("ADA")) # None
print(pattern.search("ADDA")) # 패턴만큼 출력
print(pattern.search("ADDDDDDDDDDA")) # 2개 이상이니 None
print()
pattern = re.compile("AD{2,6}A")
print("{n,m} : 최소 n, 최대 m")
print(pattern.search("ADA")) # 범위내에 만족하지 못함
print(pattern.search("ADDA")) # 최소 2개에 조건 만족
print(pattern.search("ADDDDDDA")) # 최대 6개 조건 만족
RPAbasic\regex 폴더 - regex3.py
import re
pattern = re.compile("[abcdefgABCDEFG]") # 각각의 or의미이기 때문에 처음만 찾음
print("[] : 괄호안에 들어가는 문자가 들어 있는 패턴")
print(pattern.search("abc123"))
print(pattern.search("DEF456"))
print()
pattern = re.compile("[a-gA-G]")
print("[-] : 패턴을 범위로 처리")
print(pattern.search("abc123"))
print(pattern.search("DEF456"))
print()
pattern = re.compile("[a-zA-Z]+")
print("[a-zA-Z] : 알파벳 전체를 패턴으로 처리")
print(pattern.search("abc123"))
print(pattern.search("DEF456"))
print()
pattern = re.compile("[^a-zA-Z0-9]")
print("[^a-zA-Z0-9] : 대괄호 안의 ^는 포함하지 않는")
print(pattern.search("abc123")) # None
print(pattern.search("#%&G456"))
print()
pattern = re.compile("[가-힣]")
print("[가-힣] : 한글 찾기")
print(pattern.search("abc123"))
print(pattern.search("가나다라"))

RPAbasic\regex 폴더 - regex4.py
import re
pattern = re.compile("[a-z]+") # 소문자만 나와야하고(최소 1~ 최대 무한대)
matched = pattern.match("Dave")
print("match()", matched) # 처음부터 매치가 안되서 안찾음
searched = pattern.search("Dave")
print("search()", searched) # 전체 조회해서 같으면 출력
# re.sub(패턴, 바꿀문자열, 원본문자열) : 찾아서 바꾸기
ori_text = "DDA D1A DDDA DA"
print("re.sub : ", re.sub("D.A", "Dave", ori_text))
# findall() : 정규식과 일치하는 모든 문자열을 찾아 리스트로 반환
print("findall : ", pattern.findall("Game of Life in Python"))
pattern = re.compile("[a-zA-Z]+")
print("re.sub findall : ", pattern.findall("Game of Life in Python"))
# finditer() : 정규식과 일치하는 모든 문자열을 찾아 iterator 객체로 반환
for m in pattern.finditer("Game of Life in Python"):
print(m) # match 형태
print("finditer : ", m.group())
# split() : 정규식을 기준으로 문자열 분리 후 리스트로 반환
pattern = re.compile(":")
print("split : ", pattern.split("python:java"))

RPAbasic\regex 폴더 - regex5.py
data_kr.xlsx 엑셀 파일 읽기
- 주민번호 칼럼을 읽어서 화면 출력, 단 주민 번호 뒷자리는 * 변경

# 원본 문자 : python VS java
# VS를 기준으로 문자열 분리 => ['python', 'java']
pattern = re.compile(" VS ") # 공백까지 확인
print(pattern.split("python VS java"))
# 엑셀파일 읽기
wb = load_workbook("./RPAbasic/crawl/download/data_kr.xlsx")
ws = wb.active
for each_row in ws.rows:
print(each_row[1].value) # 값 출력 확인
# 찾아야하는 패턴 : 주민등록번호 뒷자리
pattern = re.compile("[0-9]{7}") # 0~9사이의 7개가 와야함.
for each_row in ws.rows:
print(re.sub(pattern, "*******", each_row[1].value))
wb.close() # 엑셀 닫기
