
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- sql연습
- 파이썬데이터분석주피터노트북
- python수업
- sql따라하기
- SQL
- matplotlib
- 맷플롯립
- 파이썬알고리즘
- 주피터노트북그래프
- 파이썬시각화
- 주피터노트북데이터분석
- SQL수업
- 주피터노트북판다스
- 주피터노트북
- 파이썬수업
- python데이터분석
- 파이썬크롤링
- SQLSCOTT
- 팀플기록
- 판다스데이터분석
- 파이썬데이터분석
- 파이썬
- 판다스그래프
- python알고리즘
- 데이터분석시각화
- 주피터노트북맷플롯립
- Python
- sql연습하기
- 파이썬차트
- 수업기록
Archives
- Today
- Total
IT_developers
Python algorithm 개념 및 실습 - 그래프(친구찾기, 친밀도) 본문
알고리즘이란 ?
- 어떤 일을 하기 위한 명령의 집합
- 문제 해결 방법을 추상화하여 각 절차를 논리적으로 기술해 놓은 것
- 어떤 문제를 해결하기 위한 절차나 방법
알고리즘 복잡도
- Complexity
- 어떤 알고리즘이 문제를 풀기 위해 해야하는 계산이 얼마나 복잡한가?
- 알고리즘의 성능을 객관적으로 평가하는 기준
- 시간복잡도(time complexity) : 실행 횟수로 판단
- 공간복잡도(space complexity) : 기억공간과 파일 공간의 사용량
- 빅오 표기법 ( Big O Notation)
- 알고리즘이 얼마나 빠른지 표시하는 방법
- 입력 데이터 크기 증가할 때 알고리즘 연산 시간(횟수)의 증가 방식
- 연산의 횟수를 비교함
- O(n) : 계산 복잡도
- O : 빅 O
- n : 연산 횟수
- O(1) : 입력 크기 n과 계산 복잡도가 무관 할때 ex) n(n+1)/2
- O(logn) : 입력 크기 n의 로그 값에 비례하여 증가 ex) 이분탐색
- O(n) : 입력 크기 n에 비례하여 복잡도 증가 ex) 최댓값, 순차탐색
- O(nlogn) : 입력 크기 n과 로그 n 값의 곱에 비례하여 복잡도 증가 ex) 병합정렬, 퀵정렬
- O(n²) : 입력 크기 n의 제곱에 비례하여 복잡도 증가 ex) 선택정렬, 삽입정렬
- O(n₂) : 입력 크기가 n 일 때, 2의 n 제곱 값에 비례하여 복잡도 증가 ex)하노이의 탑
그래프
- 각 꼭짓점(vertex)들의 관계를 연결한 형태
- 파이썬에서는 리스트와 딕셔너리를 이용해서 표현 가능

친구찾기 : 여덟 명의 사람들이 친구 관계를 맺고 있을 때 리스트와 딕셔너리를 이용하여 그래프 표현
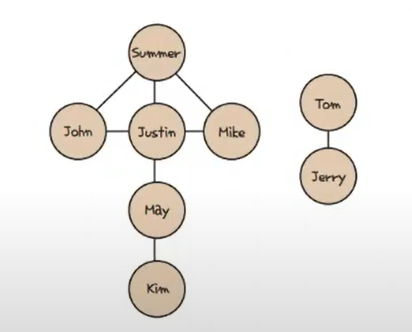
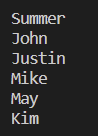
frend_info = {
"Summer": ["John", "Justin", "Mike"],
"John": ["Summer", "Justin"],
"Justin": ["John", "Summer", "Mike", "May"],
"Mike": ["Summer", "Justin"],
"May": ["Justin", "Kim"],
"Kim": ["May"],
"Tom": ["Jerry"],
"Jerry": ["Tom"],
}
# g = 그래프, name = 이름
def all_friends(g, name):
# 앞으로 처리 해야 할 사람들을 큐(리스트)에 저장
queue = []
# 큐에 추가한 사람들 기록(set) - 중복 안하려고
end = set()
# name 을 queue, end 추가
queue.append(name)
end.add(name)
# 반복문 : 큐에 사람이 있을 때까지
while queue:
# 큐에서 한 사람씩 꺼내서
person = queue.pop(0)
# 꺼낸 이름 출력
print(person)
# 반복문 - 꺼낸 이름을 키 값으로 해서 아직 큐에 추가된 적이 없는 사람을
for p in g[person]:
# 조건 존재하지 않으면
# 큐에 추가하고 집합에도 추가
if p not in end:
queue.append(p)
end.add(p)
if __name__ == "__main__":
all_friends(frend_info, "Summer")
all_friends(frend_info, "Summer")
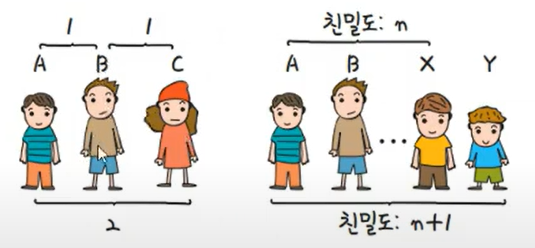
친밀도 : A와 B가 친구, B와 C가 친구일 때, A를 기준으로 B의 친밀도는 1, B와 C의 친밀도는 1 이므로, A와 C의 친밀도는 2가됨.
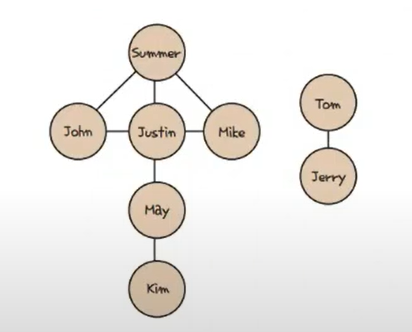
frend_info = {
"Summer": ["John", "Justin", "Mike"],
"John": ["Summer", "Justin"],
"Justin": ["John", "Summer", "Mike", "May"],
"Mike": ["Summer", "Justin"],
"May": ["Justin", "Kim"],
"Kim": ["May"],
"Tom": ["Jerry"],
"Jerry": ["Tom"],
}
# 이름과 친밀도와 하나로
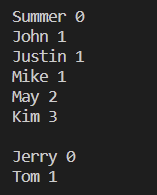
def print_all_friends(g, name):
# 앞으로 처리 해야 할 사람들을 큐(리스트)에 저장
queue = []
# 큐에 추가한 사람들 기록(set) - 중복 안하려고
end = set()
# name 을 queue, end 추가
# 튜플 구조 : (name,0), append() : 함수
queue.append((name, 0)) # queue = [("Summer",0),("Justin",1)]
end.add(name)
# 반복문 : 큐에 사람이 있을 때까지
while queue:
# 큐에서 한 사람씩 꺼내서
person, d = queue.pop(0)
# 꺼낸 이름 출력
print(person, d)
# 반복문 - 꺼낸 이름을 키 값으로 해서 아직 큐에 추가된 적이 없는 사람을
for p in g[person]:
# 조건 존재하지 않으면
# 큐에 추가하고 집합에도 추가
if p not in end:
queue.append((p, d + 1))
end.add(p)
if __name__ == "__main__":
print_all_friends(frend_info, "Summer")
print()
print_all_friends(frend_info, "Jerry")
'Python' 카테고리의 다른 글
| Python algorithm 개념 및 실습 - 가짜 동전 (1) | 2022.09.20 |
|---|---|
| Python algorithm 개념 및 실습 - 미로 찾기 (0) | 2022.09.20 |
| Python algorithm 개념 및 실습 - 큐와 스택(회문찾기) (0) | 2022.09.19 |
| Python algorithm 개념 및 실습 - 이진 탐색 (0) | 2022.09.19 |
| Python algorithm 개념 및 실습 - 정렬(2) (0) | 2022.09.18 |
'Python' Related Articles
more




Comments