RPA(Robotic Process Automation)
- 웹, 윈도우, 어플리케이션(엑셀 등)을 사전에 설정한 시나리오에 따라 자동적으로 작동하여 수작업을 최소화하는 일련의 프로세스
- RPA 사용 소프트웨어
- Uipath, BluePrism, Automation Anywhere, WinAutomation
- RPA 라이브러리
- pyautogui, pyperclip, selenium
크롤링 : 웹 사이트, 하이퍼링크, 데이터 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것
URL 작업 - urllib 라이브러리 존재(파이썬)
- request
- urlretrieve()
- 요청하는 url의 정보를 파일로 저장
- 리턴값이 튜플 형태로 옴
- csv 파일, api 데이터 등 많은 양의 데이터를 한번에 저장
- urlopen()
- 다운로드 하지 않고 정보를 메모리에 올려서 분석
- read() : 메모리에 있는 정보를 읽어옴
RPAbasic\crawl\urllib 폴더 - urlretrieve1.py
import urllib.request as req
# 다운로드 받을 경로 폴더 생성
path = "./RPAbasic/crawl/download/"
# 요청 url, 다운로으 경로+ 파일명
try:
file1, header1 = req.urlretrieve(url, path + "google.html")
except Exception as e:
print(e)
else:
print(header1)
print("성공")

RPAbasic\crawl\urllib 폴더 - urlretrieve2.py
이미지, html 파일 다운로드 : 검색 후 이미지 주소 복사
import urllib.request as req
img_url = "https://search.pstatic.net/common/?src=http%3A%2F%2Fblogfiles.naver.net%2FMjAyMjA1MTRfMjIx%2FMDAxNjUyNTE3NDYwOTI5.N1XANvyVbrVCuMUk5h8jG9UuKx4wzn6hN7YgHNhkqtwg.qJ_25tjAdJSlmkmXlcXoAmBem4JRLfQqgYQWhtsBpokg.PNG.feelgoodkjg%2F20220514_173526.png&type=sc960_832"
# 다운로드 받을 경로
path = "./RPAbasic/crawl/download/"
# 요청 url, 다운로으 경로+ 파일명
try:
file1, header1 = req.urlretrieve(img_url, path + "cat.png")
file2, header2 = req.urlretrieve(file_url, path + "naver.html")
except Exception as e:
print(e)
else:
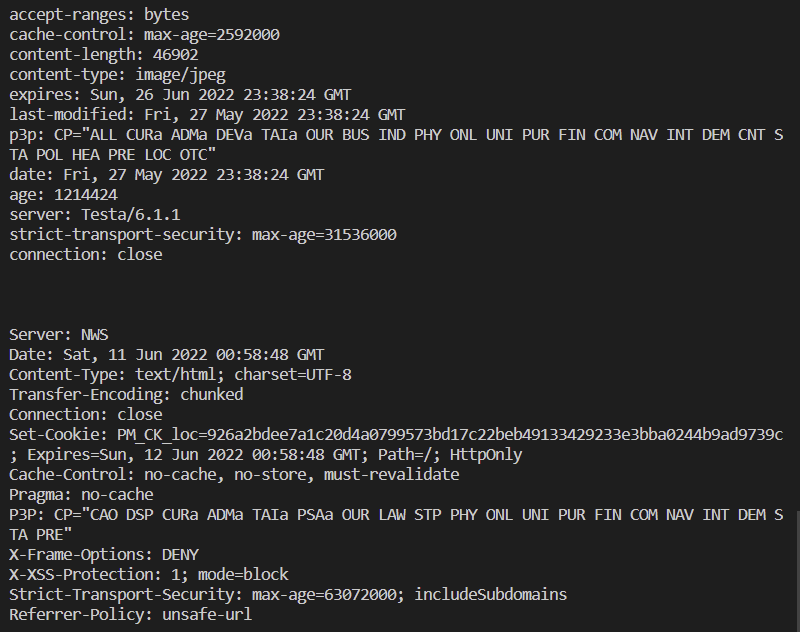
print(header1)
print()
print(header2)
RPAbasic\crawl\urllib 폴더 - urlopen1.py
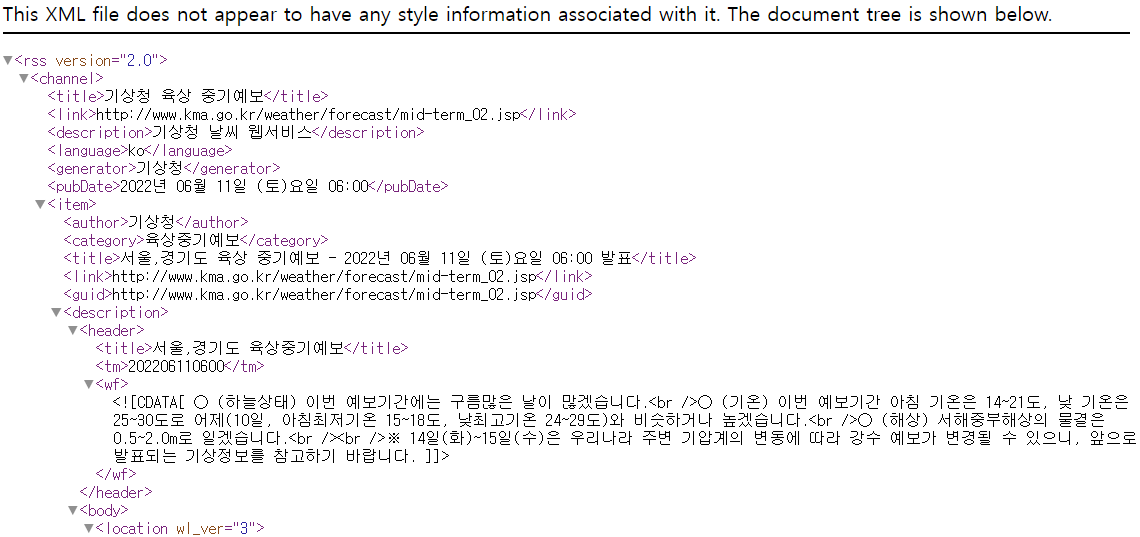
기상청 날씨누리 사이트 -> RSS
import urllib.request as req
res = req.urlopen(weather_url).read().decode("utf-8")
# 양이 많으니 4000개까지만 출력
print(res[:4000])
RSS (Really Simple Syndication, Rich Site Summary)
- 블로그처럼 컨텐츠 업데이트가 자주 일어나는 웹사이트에서, 업데이트된 정보를 쉽게 구독자들에게 제공하기 위해 XML을 기초로 만들어진 데이터 형식
RPAbasic\crawl\urllib 폴더 - urlopen2.py
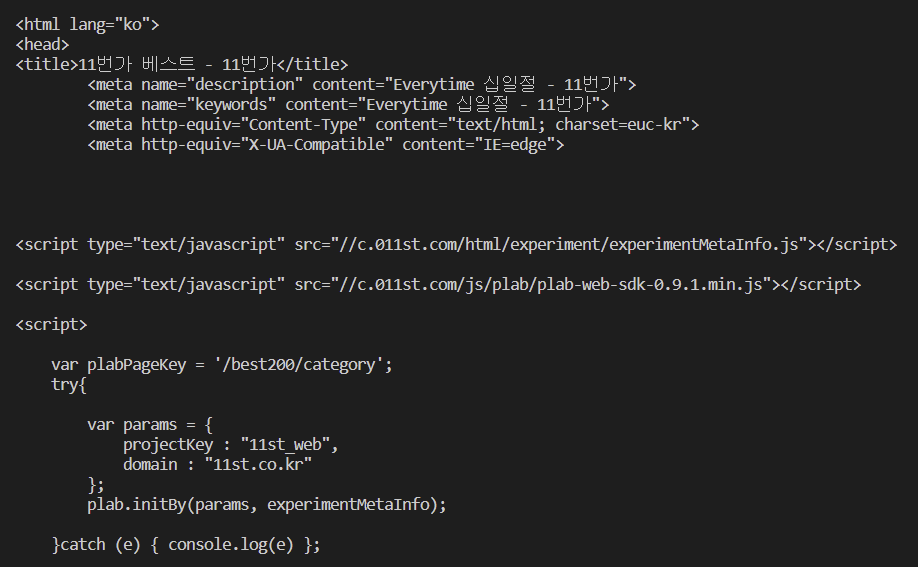
11번가 - 베스트
import urllib.request as req
try:
res = req.urlopen(url)
# content = res.read().decode("utf-8") # 'utf-8' codec can't decode byte 0xb9 in position 141: invalid start byte
# 11번가는 인코딩 방식이 charset = euc-kr로 되어 있음
# F12 Soures 인코딩 방식 확인
content = res.read().decode("euc-kr")
except Exception as e:
print(e)
else:
print(content[:3000])
print(res.info())
RPAbasic\crawl\urllib 폴더 - urlopen3.py
url 열어서 데이터 분석 후 저장
import urllib.request as req
# urlretrieve2.py에서 사용한 경로
target_url = [
"https://search.pstatic.net/common/?src=http%3A%2F%2Fblogfiles.naver.net%2FMjAyMjA1MTRfMjIx%2FMDAxNjUyNTE3NDYwOTI5.N1XANvyVbrVCuMUk5h8jG9UuKx4wzn6hN7YgHNhkqtwg.qJ_25tjAdJSlmkmXlcXoAmBem4JRLfQqgYQWhtsBpokg.PNG.feelgoodkjg%2F20220514_173526.png&type=sc960_832",
]
# 다운로드 받을 경로
path_list = [
"./RPAbasic/crawl/download/cat.png",
"./RPAbasic/crawl/download/naver.html",
]
# 오픈해서 데이터 저장까지
for i, url in enumerate(target_url):
try:
res = req.urlopen(url)
contents = res.read()
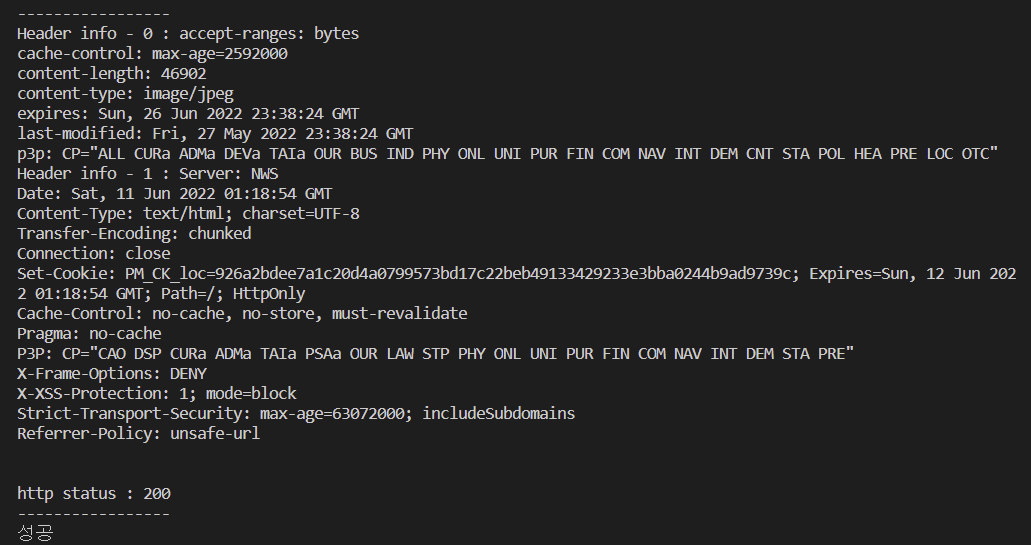
print("-----------------")
print("Header info - {} : {}".format(i, res.info()))
print("http status : {}".format(res.getcode()))
print("-----------------")
# 파일 저장코드. wb : 이미지라서 사용
with open(path_list[i], "wb") as c:
c.write(contents)
except Exception as e:
print(e)
else:
print("성공")
RPAbasic\crawl\urllib 폴더 - urlopen4.py
영화징흥위원회 api에서 영화 정보 가지고 와서 txt 파일로 저장
import urllib.request as req
# 다운로드 받을 경로
path = "./RPAbasic/crawl/download/"
try:
contents = req.urlopen(url).read().decode("utf-8") # 파일읽기
except Exception as e:
print(e)
else:
with open(path + "movie.txt", "w", encoding="utf-8") as f: # 파일 저장
f.write(contents)
print("성공")
RPAbasic\crawl\urllib 폴더 - urlencode1.py
동적
from urllib.request import urlopen
from urllib.parse import urlencode
# 접속한 주소에 ip주소를 찍어줌.
url = api + "?" + "format=json"
print(res) # {"ip":"121.160.42.16"}
values = {"format": "json"} # 그냥 실행하면 하면 타입오류
# url = api + "?" + values #TypeError: can only concatenate str (not "dict") to str
url = api + "?" + urlencode(values) # urlencode : 브라우저를 직접 띄워서 일어날수 있는 문제를 해결해줘야함.
res = urlopen(url).read().decode("utf-8")
print(res)
RPAbasic\crawl\urllib 폴더 - urlencode2.py
from urllib.request import urlopen
from urllib.parse import urlencode
# 네이버에서 영화 검색
# query=%EC%98%81%ED%99%94 == '영화' ==> 한글, 공백 문자 자동 인코딩
# 에러 발생. 한글부분을 인식하지 못함
param = {"query": "영화"}
url = (
+ urlencode(param)
)
try:
res = urlopen(url).read().decode("utf-8")
except:
print("URL Error")
else:
print(res)
 전체 코드가 출력됨
전체 코드가 출력됨
RPAbasic\crawl\urllib 폴더 - mois.py
행정안전부 게시판 목록 가져오기
뉴스 , 소식 - RSS 주소
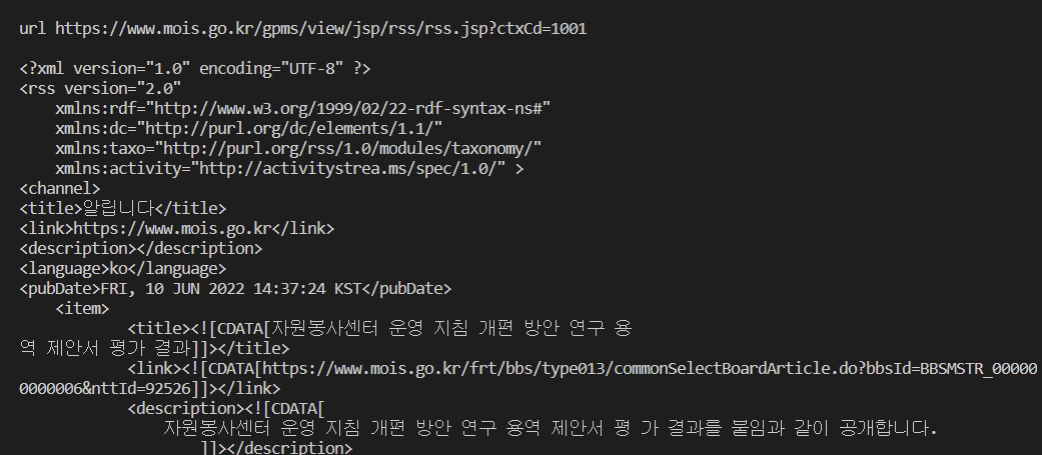
https://www.mois.go.kr/gpms/view/jsp/rss/rss.jsp?ctxCd=1001
from urllib.request import urlopen
from urllib.parse import urlencode
# 자주 바뀌는 부분 params로 받기
params = []
for num in [1001, 1012, 1013, 1014]:
# 딕셔너리 구조로 붙여넣기. 숫자는 자주 바뀜
params.append(dict(ctxCd=num))
# print(params) #자료 확인
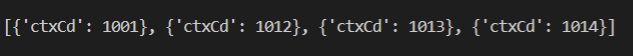
try:
for c in params:
param = urlencode(c)
url = url + "?" + param
print("url {}".format(url))
data = urlopen(url).read().decode("utf-8")
print()
print(data)
except:
print("Error")
사이트를 크롤링할 때 서버에서 파이썬 프로그램인지 브라우저인지 알 수 있고, 파이썬 프로그램으로 들어갔을 시 서버에서 막는게 가능.
RPAbasic\crawl\fake 폴더 - fake1.py
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
try:
request_url = Request(url)
res = urlopen(request_url).read().decode("utf-8")
print(res)
print(request_url.header_items()) # [('Host', 'n.news.naver.com'), ('User-agent', 'Python-urllib/3.10')] : 파이썬 버전
except Exception as e:
print(e)
Python-urllib/3.10가 아닌 브라우저로 서치하는 것 처럼 보여주기
라이브러리 설치 : pip install fake_useragent

# 설치 후 fake 사용
try:
userAgent = UserAgent()
headers = {"user-agent": userAgent.chrome}
request_url = Request(url, headers=headers)
res = urlopen(request_url).read().decode("utf-8")
# print(res) # 내용확인
print(request_url.header_items()) # Chrome/27.0.1453.93 Safari/537.36') 크롬 버전으로 바뀜
except Exception as e:
print(e)

RPAbasic\crawl\fake 폴더 - fake2.py
from fake_useragent import UserAgent
from urllib.request import urlopen
userAgent = UserAgent() # 객체 생성
# 만들고 싶은 브라우저 형태로 만들어 낼 수 있음
print(userAgent.ie)
print(userAgent.msie)
print(userAgent.chrome)
print(userAgent.safari)
print(userAgent.opera)
print(userAgent.firefox)
print(userAgent.random)
RPAbasic\crawl\urllib 폴더 - daum_kosdaq.py
다음 증권 사이트 - 인기 검색 리스트 가져오기
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
import json
import csv
# html 태그가 출력됨. 인기 검색은 들어있지 않음. 동적으로 넣어서 나오지 않음.
try:
res = urlopen(url).read().decode("utf-8")
print(res)
except Exception as e:
print(e)
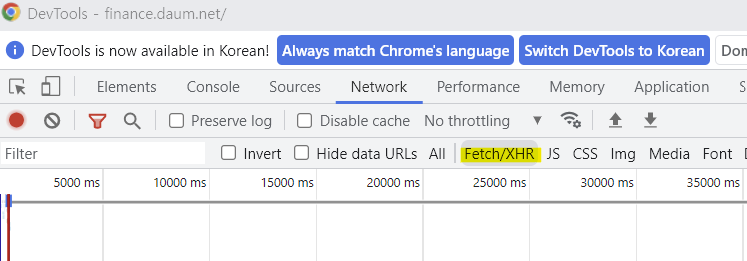
동적인 부분만 확인 가능. 동적으로 만들어진 페이지는 실제로 가지고 있는 주소를 찾아야함.
Fetch/XHR : Ajax 부분
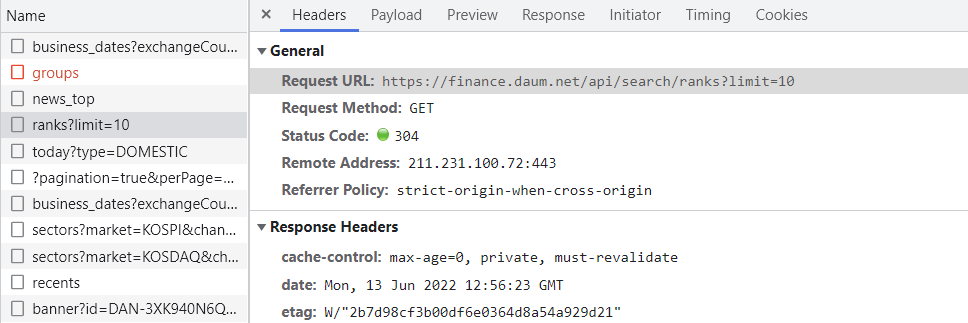
Request URL: 보이는 URL과 다른 주소를 가지고 있음. 권한없음으로 막혀있음.:
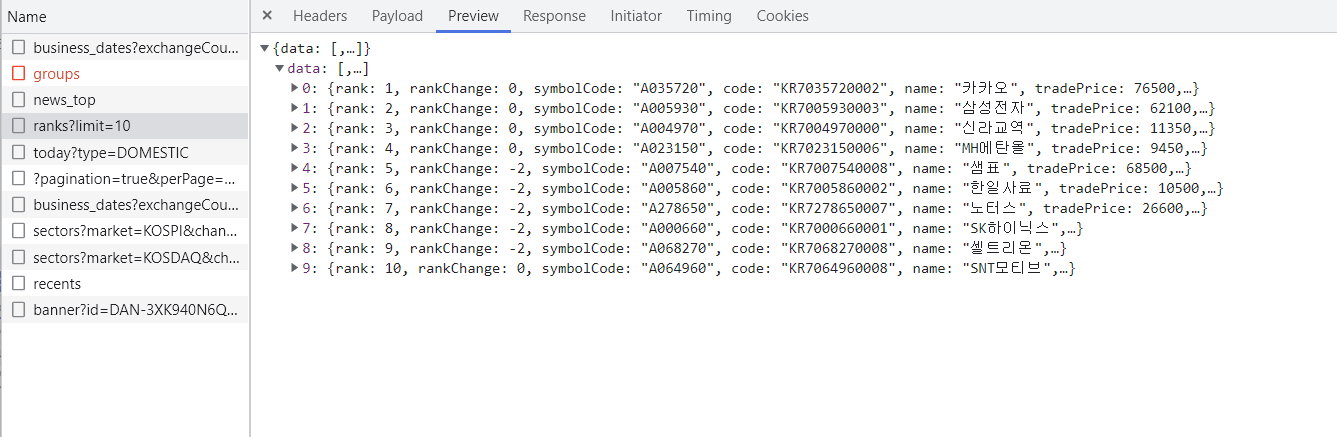
Preview에 확인 했더니 원하던 정보들(인기 검색)이 담겨있음
브라우저에서 접근했던 방식 그대로 사용하여 크롤링 해야함
크롤링이 쉽지 않지만, 사이트마다 규칙을 알면 가지고 올 수 있음
Request Headers - refere 주소 확인
- Request URL 요청을 들어가기 전에 있던 페이지
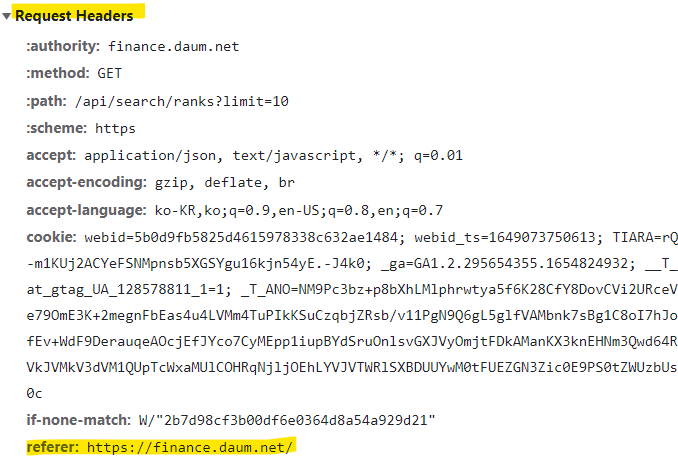
동적으로 만들어진 페이지는 실제로 가지고 있는 주소를 찾아야함.
어떤 곳에 담아져 있는지 하나하나 클릭해서 봐야함.
403에러가 떴을 때 referer 주소 확인
# UserAgent브라우저에서 들어가는것처럼
# 다운로드 기본경로
path = "./RPAbasic/crawl/download/"
# 빈 리스트 생성
data = []
try:
res = urlopen(Request(url, headers=headers)).read().decode("utf-8")
# json ==> dict 구조 변경
rank_json = json.loads(res)["data"]
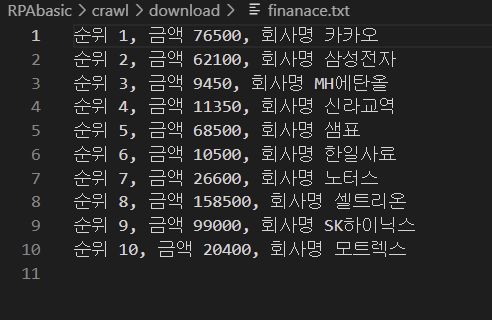
for item in rank_json:
print(
"순위 {}, 금액 {}, 회사명 {}".format(
item["rank"], item["tradePrice"], item["name"]
)
)
data.append(item)
with open(path + "finanace.txt", "a", encoding="utf-8") as txt, open(
path + "finanace.csv", "a", encoding="utf-8", newline=""
) as csvfile:
# 텍스트 저장
txt.write(
"순위 {}, 금액 {}, 회사명 {}\n".format(
item["rank"], item["tradePrice"], item["name"]
)
)
# csv 저장
output = csv.writer(csvfile)
# 헤더명
output.writerow(data[0].keys())
for row in data:
output.writerow(row.values()) # value 저장
except Exception as e:
print(e)

txt파일, csv 저장 확인.