RPA(Robotic Process Automation)
- 웹, 윈도우, 어플리케이션(엑셀 등)을 사전에 설정한 시나리오에 따라 자동적으로 작동하여 수작업을 최소화하는 일련의 프로세스
- RPA 사용 소프트웨어
- Uipath, BluePrism, Automation Anywhere, WinAutomation
- RPA 라이브러리
- pyautogui, pyperclip, selenium
크롤링 : 웹 사이트, 하이퍼링크, 데이터 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것
URL 작업 - urllib 라이브러리 존재(파이썬)
- request
- urlretrieve()
- 요청하는 url의 정보를 파일로 저장
- 리턴값이 튜플 형태로 옴
- csv 파일, api 데이터 등 많은 양의 데이터를 한번에 저장
- urlopen()
- 다운로드 하지 않고 정보를 메모리에 올려서 분석
- read() : 메모리에 있는 정보를 읽어옴
파싱 라이브러리 설치 : pip install beautifulsoup4
파서 라이브러리 설치 : pip install lxml

requests + beautifulsoup4 조합
- 객체 생성 후 사용 가능
- 객체 생성(페이지소스, 파서)
- parser : lxml 사용. c 언어 기반으로 되어 있음
- parser : html.parser(기본) - 설치 필요없음.
- lxml이 html.parser 보다 빠름.
- 특정 엘리먼트 찾기
- 태그 이용(가장 처음에 만나는 태그만 가져옴)
- find() : find("찾을 태그명", class_="클래스 명")
- find_all()
- find_*()
RPAbasic\crawl\beautifulsoup 폴더 - bs1.py
다음 사이트에 첫 뉴스 주소
import requests
from bs4 import BeautifulSoup
# 다음에 있는 첫 뉴스 주소
print(res.text) # 자료확인
soup = BeautifulSoup(res.text, "lxml") # html 형식으로 바뀜
print(soup) # print(res.text) 같은 값으로 출력
print(soup.prettify()) # 줄 정렬이 되어 출력(들여쓰기)
# <head> 태그 안 내용 가져오기
print(soup.head)

# <body> 태그 내용 가져오기
print(soup.body)
# title 태그
print(soup.title) # title
print(soup.title.name) # 태그 명
print(soup.title.get_text()) # 태그 안 text
print(soup.title.string) # 태그 안 text
RPAbasic\crawl\beautifulsoup 폴더 - bs2.py
네이버 경제 뉴스 특정 요소 찾기
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
# 네이버 경제 뉴스 주소
headers = {"user-agent": UserAgent().chrome}
# res = requests.get(url)
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
# 특정 엘리먼트 찾기 - 1. 태그 이용(가장 처음에 만나는 태그만 가져오기)
print( soup.h2)
# 'Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) 파이썬으로 들어갔을 때 거부 당함. ==> UserAgent 사용
# 특정 엘리먼트 찾기 -2. find(), find_all(), find_*() : 다양한 메소드가 올수 있음
h2_ele = soup.find("h2", class_="media_end_head_headline")
print(h2_ele)
값은 똑같이 나옴.

샘플 데이터 만들기
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object, or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str() function returns a str
www.crummy.com
Quick Start 복사해서 RPAbasic\crawl\beautifulsoup 폴더에 story.html 로 저장
추가사항
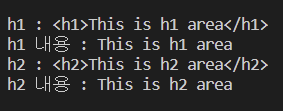
<h1>This is h1 area</h1>
<h2>This is h2 area</h2>
id="link3" data-io="tillie"
RPAbasic\crawl\beautifulsoup 폴더 - bs3.py
태그 찾기
웹에서 불러 올게 아니라서 requests는 필요 없음. story.html 활용
# 문서 가져오기
with open("./RPAbasic/crawl/beautifulsoup/story.html", "r") as f:
html = f.read()
soup = BeautifulSoup(html, "lxml")
print(soup.prettify()) # 자료확인

# 태그명으로 찾기
title = soup.title
print("title : {}".format(title))
print(f"title : {title}")
print("title 내용 : {}".format(title.get_text()))
print("title 부모 태그 : {}".format(title.parent))

# h1 태그 찾기
print(f"h1 : {soup.h1}")
print(f"h1 내용 : {soup.h1.get_text()}")
# h2 태그 찾기
print(f"h2 : {soup.h2}")
print(f"h2 내용 : {soup.h2.get_text()}")
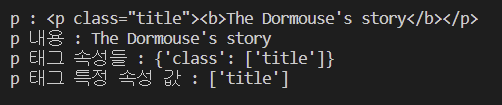
# p 태그 찾기 : 어떤 p태그를 찾을껀지.
p1 = soup.p # 제일 처음에 있는 p태그
print(f"p : {p1}")
print(f"p 내용 : {p1.get_text()}")
print(f"p 태그 속성들 : {p1.attrs}")
print(f"p 태그 특정 속성 값 : {p1['class']}")
# b 태그 찾기
print(f"b : {soup.b}")
print(f"b 내용 : {soup.b.get_text()}")

# a 태그 찾기
print(f"a : {soup.a}") # 가장 처음에 만나는 a
print(f"a 내용 : {soup.a.get_text()}")

RPAbasic\crawl\beautifulsoup 폴더 - bs5.py
find(), find_all(), find_*() 로 태그 찾기
from bs4 import BeautifulSoup
# 문서 가져오기
with open("./RPAbasic/crawl/beautifulsoup/story.html", "r") as f:
html = f.read()
soup = BeautifulSoup(html, "lxml")
print(soup.prettify()) # 자료확인

# 첫번째 p 태그 찾기
# p1 = soup.p
# soup.find("p", class_="title")
p1 = soup.find("p", "title")
print(p1)

# 형제 p 태그 찾기
# 찾아놓은 기반으로 그 다음 태그 찾기
p2 = p1.find_next_sibling("p")
print(f"p 두번째 : {p2}")
print(f"p 두번째 내용 : {p2.get_text()}") # p가 가지고 있지 않은 자식들이 가지고 있는 내용도 출력됨
print(f"p 두번째 속성들 : {p2.attrs}")
print(f"p 두번째 특정 속성 값 : {p2['class']}")

# 세번째 p 찾기
# p3 = p2.next_sibling.next_sibling #속성으로 만든 상태
p3 = p2.find_next_sibling("p") # 함수로 만든 상태
print(f"p 세번째 : {p3}")
print(f"p 세번째 내용 : {p3.get_text()}")
print(f"p 세번째 속성들 : {p3.attrs}")
print(f"p 세번째 특정 속성 값 : {p3['class']}")

# 첫번째 a 태그 찾기
a1 = soup.a
# 두번째 a 찾기
a2 = a1.find_next_sibling("a")
print(f"a 두번째 : {a2}")
print(f"a 두번째 내용 : {a2.get_text()}")
print(f"a 두번째 속성들 : {a2.attrs}")
print(f"a 두번째 특정 속성 값 : {a2['id']}") # id 값 가지고 오기

# 앞쪽에 있는 요소 찾기 : find_previous_sibling
# p2의 앞쪽에 있는 태그 찾기
p1 = p2.find_previous_sibling("p")
print(f"p1 : {p1}")
print(f"p1 내용 : {p1.get_text()}")
print(f"p1 태그 속성들 : {p1.attrs}")
print(f"p1 태그 특정 속성 값 : {p1['class']}")
for v in p2.next_element:
print(v, end="")

RPAbasic\crawl\beautifulsoup 폴더 - bs6.py
find(), find_all(), find_*() 로 태그 찾기
from bs4 import BeautifulSoup
# 문서 가져오기
with open("./RPAbasic/crawl/beautifulsoup/story.html", "r") as f:
html = f.read()
soup = BeautifulSoup(html, "lxml")
# 첫번째 p 태그
p1 = soup.find("p") # p1 = soup.p 같은 방법
print(p1)

# 문서에서 원하는 부분 찾기. 구조 개념은 아님. 단독으로 찾는 방법
p2 = soup.find("p", class_="story")
print(f"p 두번째 : {p2}")
print(f"p 두번째 내용 : {p2.get_text()}")
print(f"p 두번째 속성들 : {p2.attrs}")
print(f"p 두번째 특정 속성 값 : {p2['class']}")

# 세번째 p 찾기
p3 = p2.find_next_sibling("p")
print(f"p 세번째 : {p3}")
print(f"p 세번째 내용 : {p3.get_text()}")
print(f"p 세번째 속성들 : {p3.attrs}")
print(f"p 세번째 특정 속성 값 : {p3['class']}")

# 첫번째 a 태그 찾기
a1 = soup.find("a")
# 두번째 a 찾기. 첫번째 a와 상관없이.
a2 = soup.find("a", id="link2")
print(f"a 두번째 : {a2}")
print(f"a 두번째 내용 : {a2.get_text()}")
print(f"a 두번째 속성들 : {a2.attrs}")
print(f"a 두번째 특정 속성 값 : {a2['id']}")

# 세번째 a
# class, id는 단독으로 사용가능
a3 = soup.find("a", id="link3")
a3 = soup.find("a", class_="sister", id="link3")
# "data-io" 속성은 한꺼번에 묶어서 가능
a3 = soup.find("a", attrs={"class": "sister", "id": "link3", "data-io": "tillie"})
print(f"a 세번째 : {a3}")
print(f"a 세번째 내용 : {a3.get_text()}")
print(f"a 세번째 속성들 : {a3.attrs}")
print(f"a 세번째 특정 속성 값 : {a3['href']}") # 링크 속성

find_all() : 모두 가져오기(리스트 값으로 돌아옴). 값이 하나여도 무조건 리스트로 출력
# a 찾기
a = soup.find_all("a")
print(a) # 값이 3개

# b 찾기
b = soup.find_all("b")
print(b) # 값이 1개

limit : 개수 지정해서 가지고 오기
a = soup.find_all("a", limit=2)
print(a)
a = soup.find_all("a", class_="sister")
print(a)

# 텍스트 노드 값 이용해서 가져오기
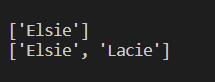
a = soup.find_all(string=["Elsie"])
print(a)
a = soup.find_all(string=["Elsie", "Lacie"])
print(a)