
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 파이썬크롤링
- 팀플기록
- 파이썬데이터분석주피터노트북
- 수업기록
- 파이썬시각화
- python알고리즘
- 파이썬데이터분석
- 파이썬알고리즘
- 맷플롯립
- 판다스그래프
- 판다스데이터분석
- matplotlib
- sql따라하기
- 파이썬수업
- 주피터노트북
- Python
- 파이썬차트
- SQLSCOTT
- python데이터분석
- sql연습
- 주피터노트북데이터분석
- 파이썬
- sql연습하기
- SQL
- 데이터분석시각화
- 주피터노트북맷플롯립
- 주피터노트북판다스
- 주피터노트북그래프
- python수업
- SQL수업
Archives
- Today
- Total
IT_developers
Python RPA(업무자동화) 개념 및 실습 - 크롤링(Beautifulsoup)(3) 본문
RPA(Robotic Process Automation)
- 웹, 윈도우, 어플리케이션(엑셀 등)을 사전에 설정한 시나리오에 따라 자동적으로 작동하여 수작업을 최소화하는 일련의 프로세스
- RPA 사용 소프트웨어
- Uipath, BluePrism, Automation Anywhere, WinAutomation
- RPA 라이브러리
- pyautogui, pyperclip, selenium
크롤링 : 웹 사이트, 하이퍼링크, 데이터 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것
URL 작업 - urllib 라이브러리 존재(파이썬)
- request
- urlretrieve()
- 요청하는 url의 정보를 파일로 저장
- 리턴값이 튜플 형태로 옴
- csv 파일, api 데이터 등 많은 양의 데이터를 한번에 저장
- urlopen()
- 다운로드 하지 않고 정보를 메모리에 올려서 분석
- read() : 메모리에 있는 정보를 읽어옴
- urlretrieve()
requests + beautifulsoup4 조합
- 객체 생성 후 사용 가능
- 객체 생성(페이지소스, 파서)
- parser : lxml 사용. c 언어 기반으로 되어 있음
- parser : html.parser(기본) - 설치 필요없음.
- lxml이 html.parser 보다 빠름.
- 특정 엘리먼트 찾기
- 태그 이용(가장 처음에 만나는 태그만 가져옴)
- find() : find("찾을 태그명", class_="클래스 명")
- find_all()
- find_*()
- CSS 선택자 이용해서 찾기
- select
- select_one
RPAbasic\crawl\beautifulsoup 폴더 - 4_실습_googlenews.py
구글 뉴스 클리핑(조각내서 가지고 오기)
import requests
from bs4 import BeautifulSoup
def main():
res = requests.get(url)
soup = BeautifulSoup(res.text, "lxml")
news_clipping = data_extract(soup)
for section in news_clipping:
for k, v in section.items():
print("{} : {}".format(k, v))
print()
def data_extract(soup):
# 원하는 요소 추출
news_list = [] # 비어있는 리스트 생성
news_item = {} # dict 구조 생성
# 뉴스 원문 url, 제목, 출처, 등록 일시 ==> 리스트 구조
# 각 개별 기사는 dict 구조로 생성
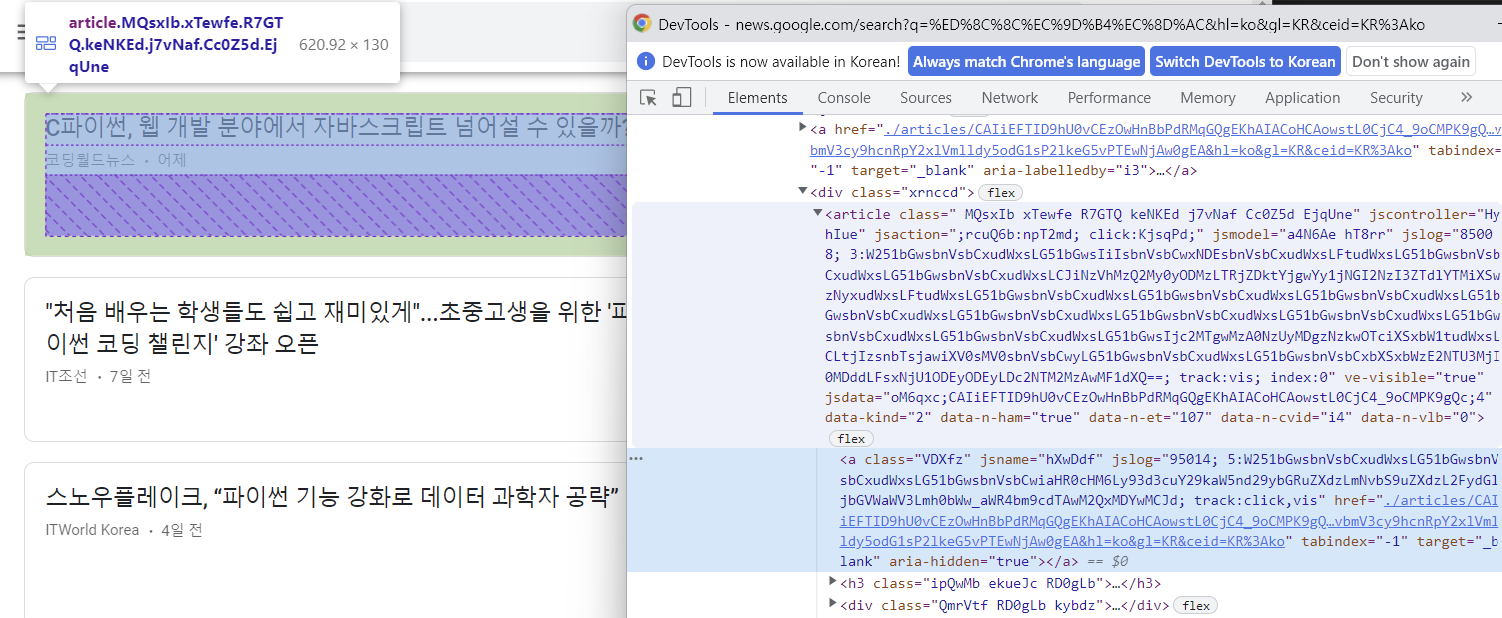
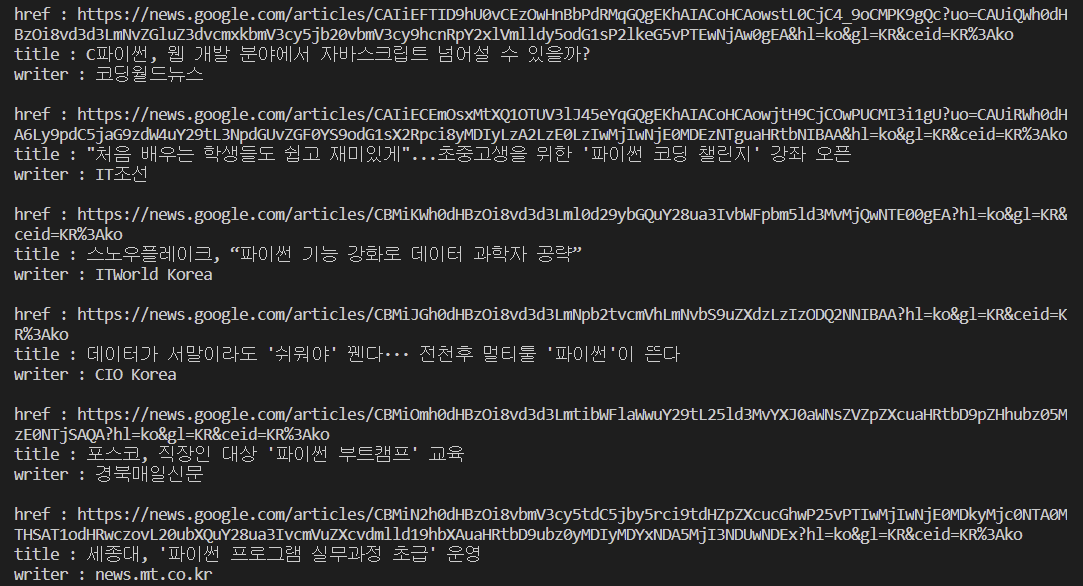
articles = soup.select("div.xrnccd > article")
for article in articles:
# print(article) # 개별로 뉴스 기사가 나오는지 확인
# 제목과 링크를 가지고 있는 태그 요소 찾기
link_title = article.select_one("h3 > a")
# 기본 주소 설정
# 기본 주소 + 상대주소
# ./articles/CBMiN2h0dHBz~~~ ==> https://news.google.com/articles~~~
news_item["href"] = (
base_url + link_title["href"][1:]
) # ./articles/~~ => .뒤에 있는 부분부터
news_item["title"] = link_title.get_text()
# 출처와 뉴스보도 시간을 가지고 있는 요소 찾기
writer_time = article.select_one("div.SVJrMe")
# 출처만 추출
news_item["writer"] = writer_time.select_one("a").get_text()
# 시간만 추출
date_time = writer_time.select_one("time")
# <time class="WW6dff uQIVzc Sksgp" datetime="2022-06-14T00:50:53Z">2시간 전</time>
if date_time:
report_date_time = date_time["datetime"].split("T")
report_date = report_date_time[0]
report_date = report_date_time[1]
else:
report_date = ""
report_time = ""
news_list.append(news_item)
news_item = {}
# 리스트 리턴
return news_list
if __name__ == "__main__":
main()
RPAbasic\crawl\beautifulsoup 폴더 - bs11.py
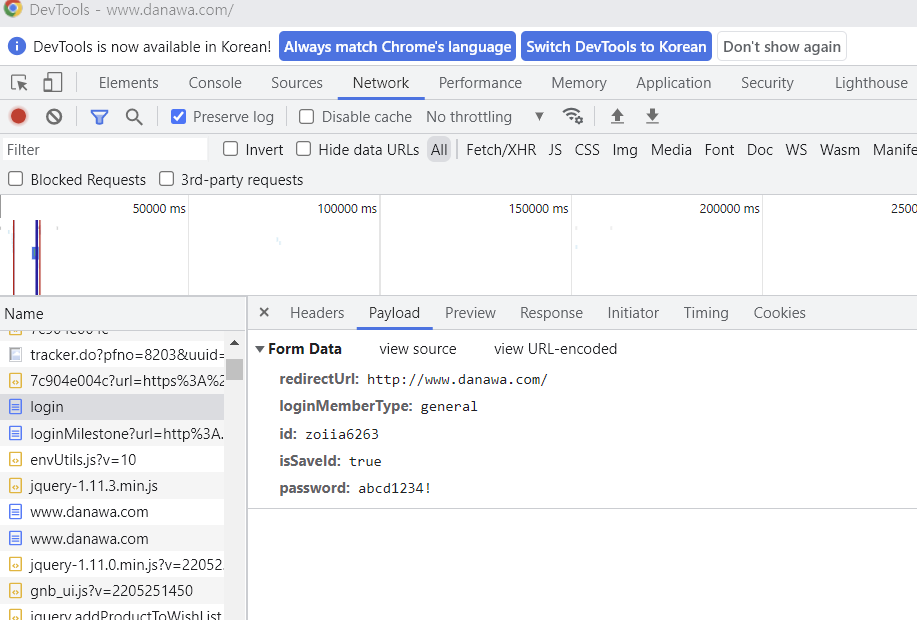
다나와 사이트- 회원가입 필요

import requests
from bs4 import BeautifulSoup
# payload
login_info = {
"loginMemberType": "general",
"id": "zoiia6263",
"isSaveId": "true",
"password": "abcd1234!",
}
# 헤더 정보
# Referer : 이전에 있던 페이지
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
}
# 로그인을 성공하면 서버는 세션을 부여해줌.
# 하나의 세션안에서 권한을 부여
# 세션을 이용.
with requests.Session() as s:
# 로그인(주소, 폼 데이터, 해더 정보)
print(res.text) # 에러 안나는지 확인
# 주문/배송 조회
# 현재 페이지 파싱
soup = BeautifulSoup(res.text, "lxml")

# 주문/배송 사이트에서 아이디 찾기
user_id = soup.find("p", class_="user")
print(user_id)
print(user_id.get_text())
if user_id is None:
# 강제 예외 발생 구문
raise Exception("Login 실패, 아이디나 비밀번호 확인")

# 상단메뉴 가져오기
# copy - selector(css selector)
# select() : element를 리스트로 가져옴
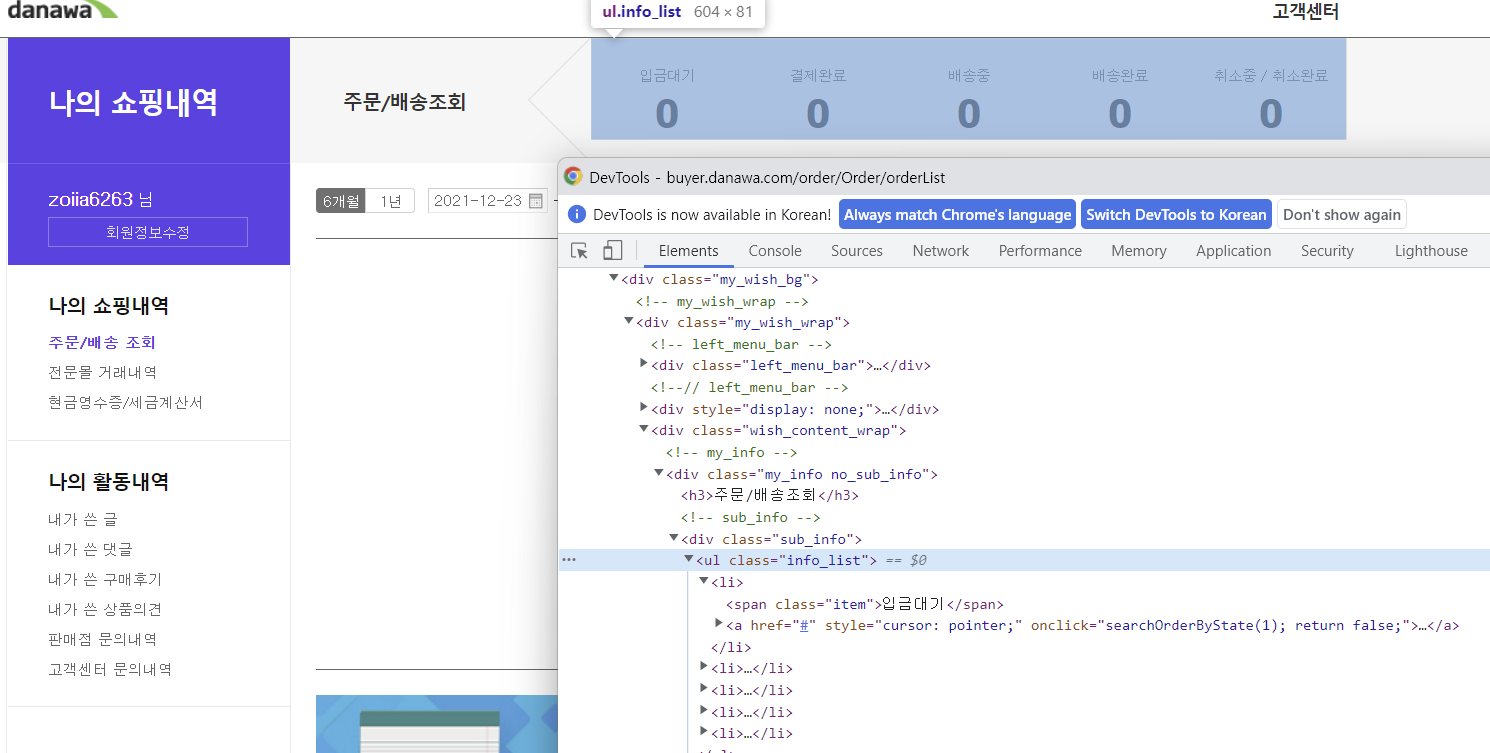
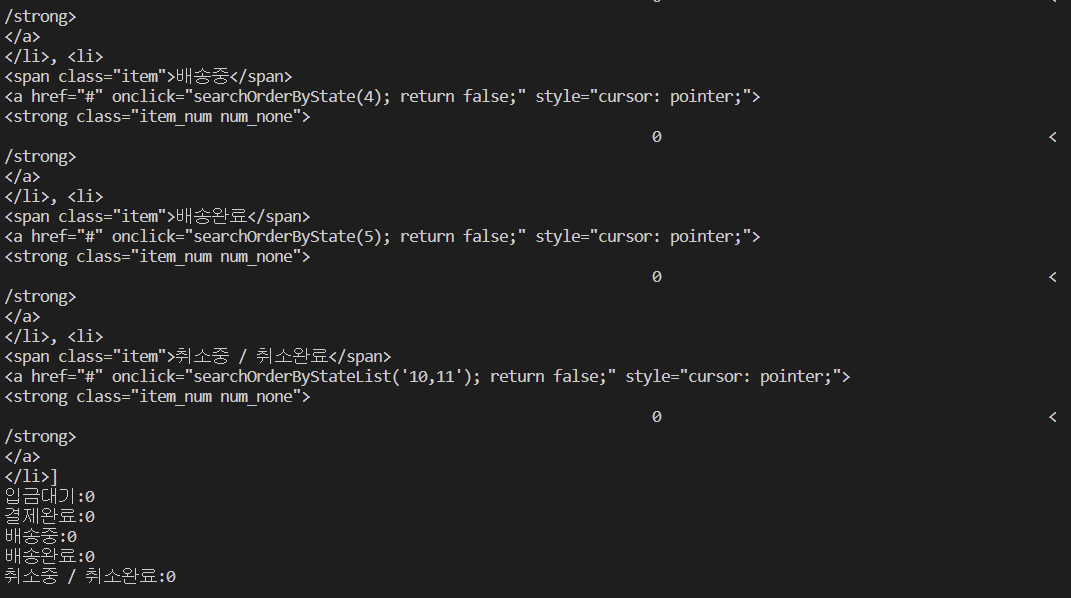
menu_list = soup.select("div > ul.info_list > li")
print(menu_list)
for menu in menu_list:
# 메뉴명, 수량
proc, val = (
menu.find("span").get_text().strip(),
menu.find("strong").get_text().strip(),
)
print(f"{proc}:{val}")
RPAbasic\crawl\beautifulsoup 폴더 - 5_실습_clien2.py
clien 팁과 강좌 게시판 크롤링 + 엑셀 저장
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
from fileinput import filename
from datetime import datetime
# 엑셀 작업
# 엑셀 파일 생성
wb = Workbook()
# 기본 시트 활성화
ws = wb.active
# A 컬럼 width 조절
ws.column_dimensions["A"].width = 80
ws.column_dimensions["B"].width = 15
# 시트명 새로 지정
ws.title = "팁과 강좌"
# 제목행 지정
ws.append(["글제목", "작성날짜"])
# 1 ~ 5 page
for page_num in range(5): # 0~4
if page_num == 0: # 1page
else:
res = requests.get(
# 파이썬은 문자로 변경해줘야함.
+ str(page_num)
)
soup = BeautifulSoup(res.text, "lxml")
# 게시판 제목
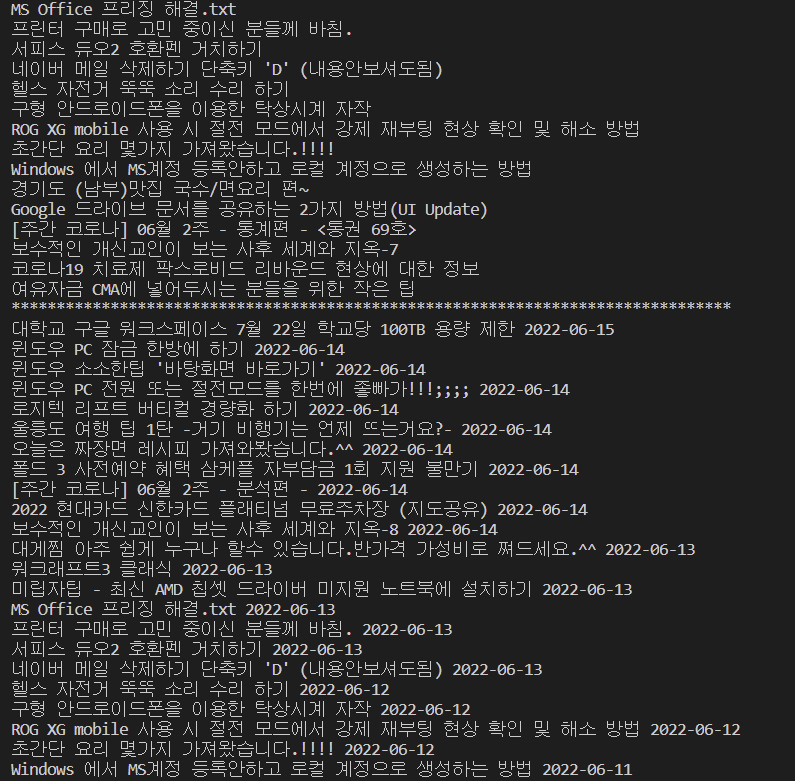
title_list = soup.select("a.list_subject > span.subject_fixed")
for title in title_list:
print(title.get_text().strip())
print("*" * 80)
# 날짜/시간 가져오기
date_list = soup.select(
"div.list_content > div.list_item > div.list_time > span > span"
)
# print(date_list)
for idx, title in enumerate(title_list):
print(title.get_text().strip(), date_list[idx].get_text()[:10])
ws.append([title.get_text().strip(), date_list[idx].get_text()[:10]])
print("*" * 80)
# 파일명 clien_220620.xlsx
# 날짜별로 저장
today = datetime.now().strftime("%y%m%d")
filename = f"clien_{today}.xlsx"
# 엑셀 저장
wb.save("./RPAbasic/crawl/download/" + filename)


RPAbasic\crawl\beautifulsoup 폴더 - 6_실습_ranking.py
네이트 연예 랭킹 뉴스 크롤링
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text, "lxml")

# 1~5위 가져오기(타이틀, 기사 작성자)
# div.postRankSubjectList.f_clear : 1위에서 5위까지
top5_list = soup.select("div.mduSubjectList > div")
print(top5_list)
# 6~50위 가져오기
# #postRankSubject li : 6위에서 50위까지
top45_list = soup.select("#postRankSubject li")
for idx, news in enumerate(top5_list, 1):
# 타이틀 (div > a> span> strong) => 자손태그로 끌면 하나라서 가능
title = news.select_one("a strong").get_text()
# 신문사
media = news.select_one("span.medium").get_text()
print(f"{idx} : {title} - {media}")
for idx, news in enumerate(top45_list, 6):
# 타이틀
title = news.select_one("a").get_text()
# 신문사
media = news.select_one("span.medium").get_text()
print(f"{idx} : {title} - {media}")

RPAbasic\crawl\beautifulsoup 폴더 - 7_실습_ranking2.py
네이트 연예 랭킹 뉴스 크롤링 후 엑셀 저장
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
from datetime import datetime
# 엑셀 작업
# 엑셀 파일 생성
wb = Workbook()
# 기본 시트 활성화
ws = wb.active
# 시트명 새로 지정
ws.title = "연예랭킹 뉴스"
ws.column_dimensions["A"].width = 70
ws.column_dimensions["B"].width = 15
# 제목행 지정
ws.append(["기사 제목", "신문사"])
soup = BeautifulSoup(res.text, "lxml")
# 1~5위 가져오기(타이틀, 기사작성자)
top5_list = soup.select("div.mduSubjectList > div")
print(top5_list)
# 6~50위 가져오기
top45_list = soup.select("#postRankSubject li")
for idx, news in enumerate(top5_list, 1):
# 타이틀 == 자손 태그로 끌기
title = news.select_one("a strong").get_text()
# 신문사(신문사 날짜)
media = news.select_one("span.medium").get_text()
print(f"{idx} : {title} - {media}")
ws.append([title, media])
for idx, news in enumerate(top45_list, 6):
# 타이틀
title = news.select_one("a").get_text()
# 신문사
media = news.select_one("span.medium").get_text()
print(f"{idx} : {title} - {media}")
ws.append([title, media])
# 파일명 nate_오늘날짜.xlsx
today = datetime.now().strftime("%y%m%d")
filename = f"nate_{today}.xlsx"
# 엑셀 저장
wb.save("./RPAbasic/crawl/download/" + filename)

RPAbasic\crawl\beautifulsoup 폴더 - gmarket2.py
G마켓 best - 컴퓨터/전자 항목 추출
import requests
from bs4 import BeautifulSoup
res = requests.get(url)
soup = BeautifulSoup(res.text, "lxml")
# 1위 ~ 100위 아이템 찾기
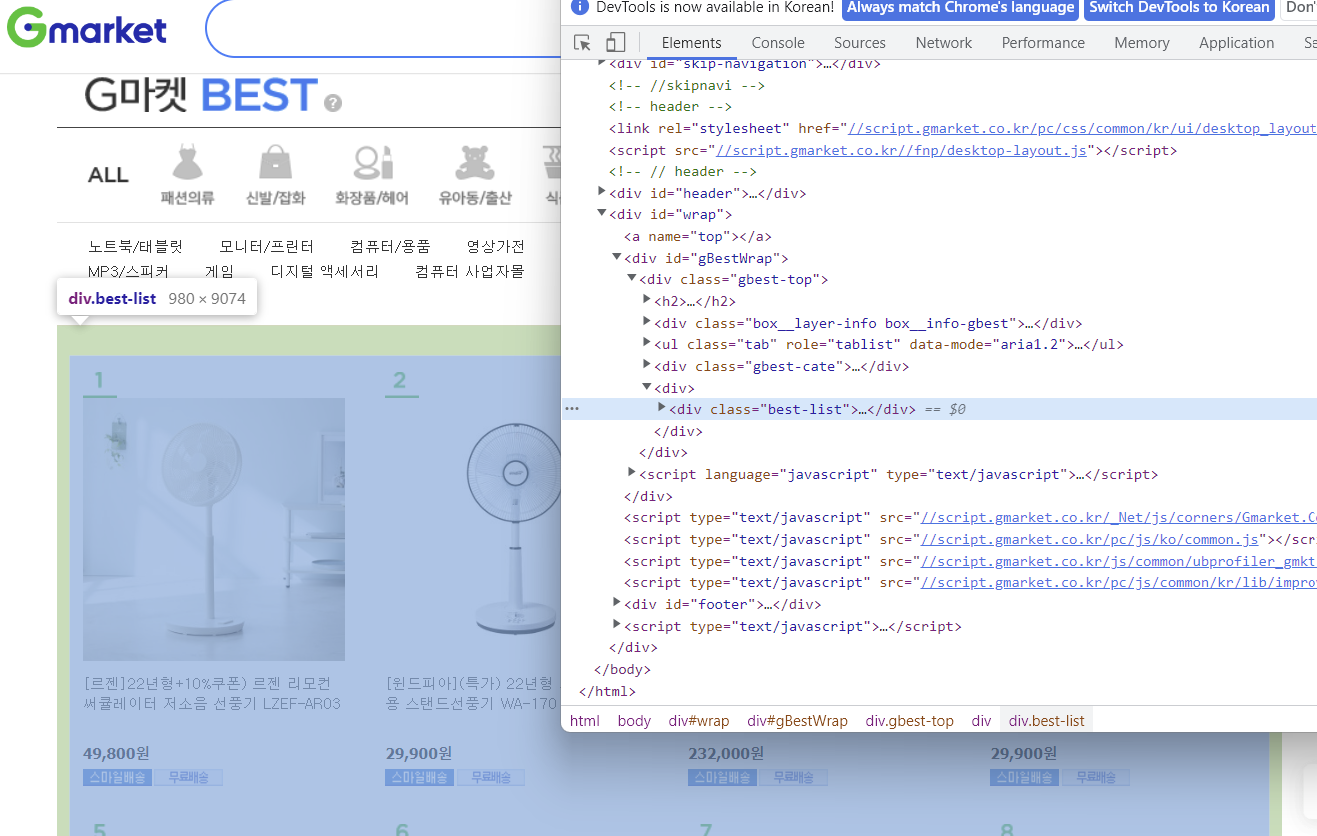
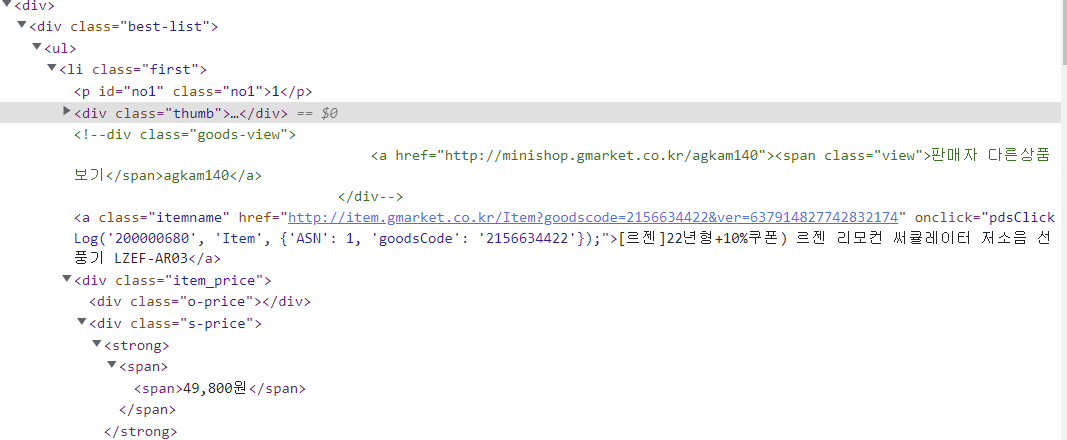
# div.best-list li : li는 자손의 개념
best_list = soup.select("div.best-list li")
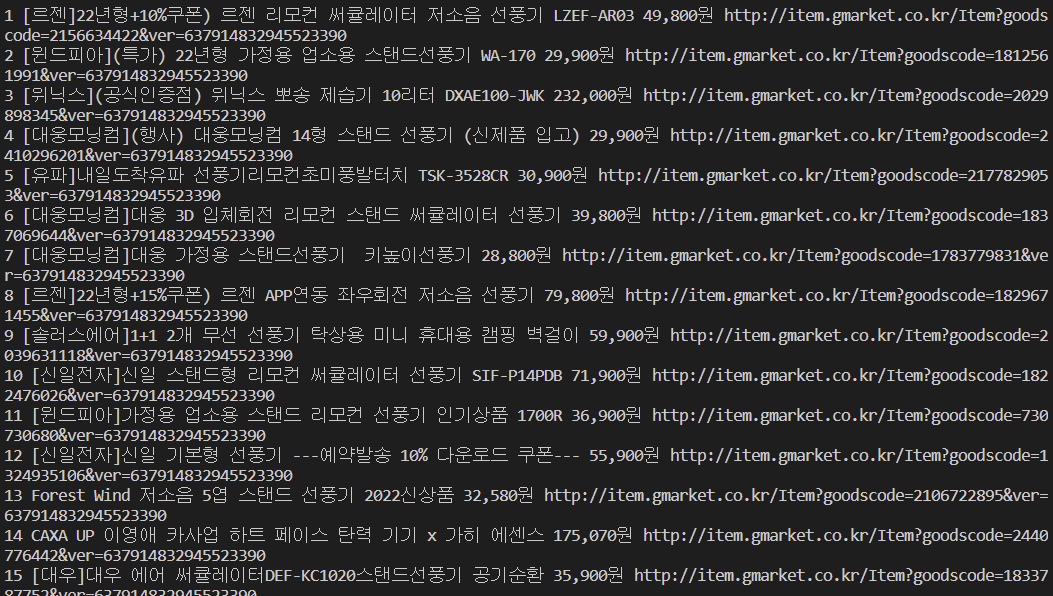
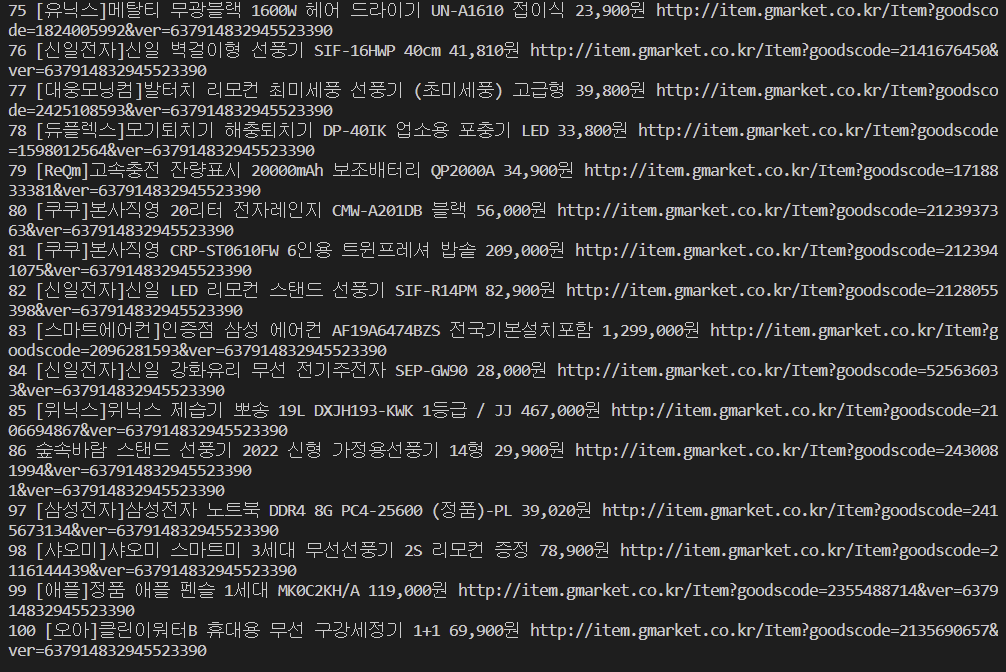
for idx, item in enumerate(best_list):
# 상품명
title = item.select_one("a.itemname")
# 가격
price = item.select_one("div.s-price span").get_text()
# 순위, 상품명, 가격, 상품상세정보 url
print(idx + 1, title.get_text(), price, title["href"])
# title["href"] 를 이용해서 requests.get() 요청
# 상세 주소 이용
product_url = title["href"]
res = requests.get(title["href"])
detail_soup = BeautifulSoup(res.text, "lxml")
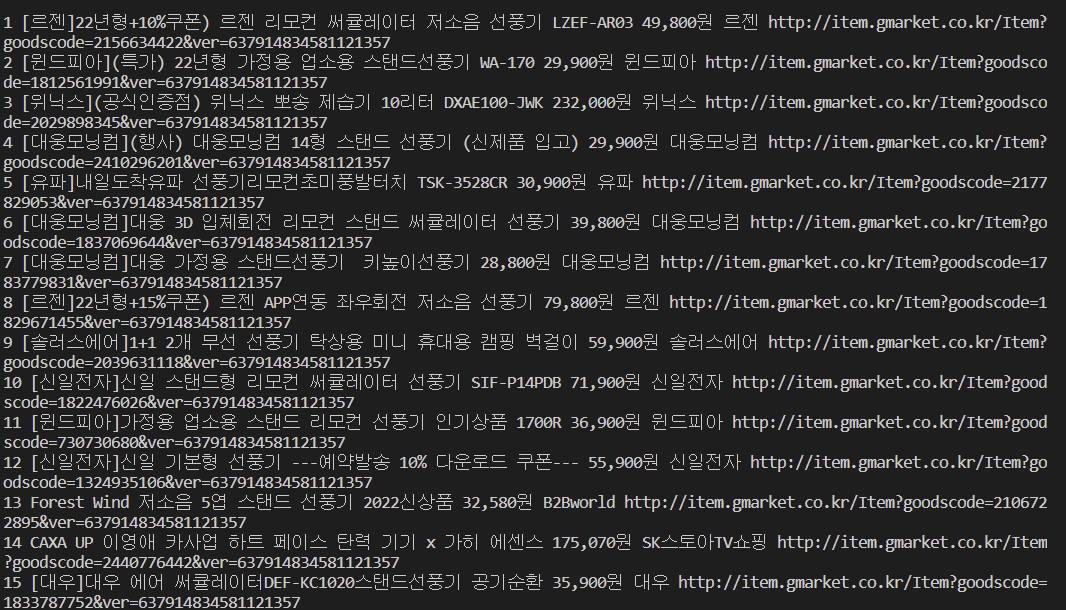
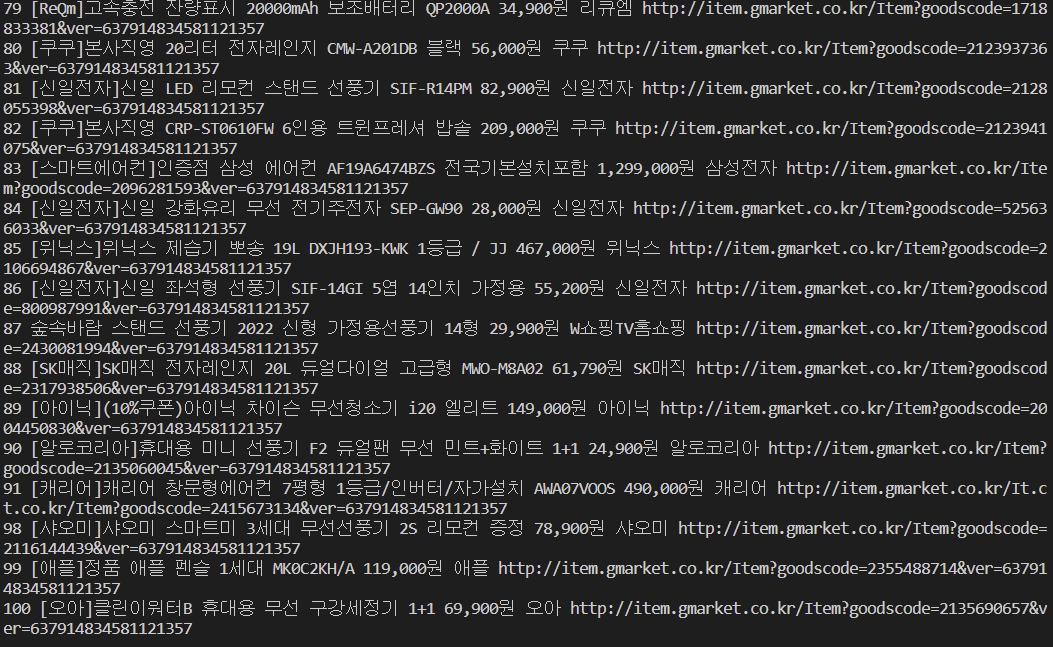
# 회사명 추출(회사명 없으면 셀러명 추출)
company = detail_soup.select_one("span.text__brand > span.text")
# 제조사가 없는 경우 셀러명 추출
# 제조사가 없음 상품을 만나면 에러문과 함께 종료
# eletment를 못찾았는데 get_text()를 호출 : AttributeError: 'NoneType' object has no attribute 'get_text'
if not company:
company = detail_soup.select_one("span.text__seller > a")
# 최종 : 순위, 상품명, 가격, 회사명, 상품상세정보 url
print(idx + 1, title.get_text(), price, company.get_text(), product_url)
RPAbasic\crawl\beautifulsoup 폴더 - gmarket3.py
G마켓 best - 컴퓨터/전자 항목 추출 + 엑셀 저장
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
from ctypes import alignment
from datetime import datetime
from openpyxl.styles import Font, Alignment
# 엑셀 작업
# 엑셀 파일 생성
wb = Workbook()
# 기본 시트 활성화
ws = wb.active
# 시트명 새로 지정
ws.title = "컴퓨터전자100"
# 상품명
ws.column_dimensions["B"].width = 50
# 가격
ws.column_dimensions["C"].width = 15
# 회사명
ws.column_dimensions["D"].width = 20
# 상세주소
ws.column_dimensions["E"].width = 80
# 제목행 지정
ws.append(["번호", "상품명", "가격", "회사명", "상품상세 정보"])
res = requests.get(url)
soup = BeautifulSoup(res.text, "lxml")
# 1위 ~ 100위 아이템 찾기
best_list = soup.select("div.best-list li")
for idx, item in enumerate(best_list):
# 상품명
title = item.select_one("a.itemname")
# 가격
price = item.select_one("div.s-price span").get_text()
# title["href"] 를 이용해서 requests.get() 요청
# 상세 주소 이용
product_url = title["href"]
res = requests.get(title["href"])
detail_soup = BeautifulSoup(res.text, "lxml")
# 회사명 추출(회사명 없으면 셀러명 추출)
company = detail_soup.select_one("span.text__brand > span.text")
# 제조사가 없는 경우 셀러명 추출
if not company:
company = detail_soup.select_one("span.text__seller > a")
# 순위, 상품명, 가격, 회사명, 상품상세정보 url
print(idx + 1, title.get_text(), price, company.get_text(), product_url) # 출력문
ws.append([idx + 1, title.get_text(), price, company.get_text(), product_url]) #엑셀저장
# 하이퍼링크 걸기(제목행 제외)
ws.cell(row=idx + 1, column=5).hyperlink = product_url
# 파일명 gmarket_오늘날짜.xlsx
today = datetime.now().strftime("%y%m%d")
filename = f"gmarket_{today}.xlsx"
# 제목 행 서식 지정
font = Font(name="Tahoma", size=14, color="01579b")
alignment = Alignment(horizontal="center")
cell_a1 = ws["A1"]
cell_a1.alignment = alignment
cell_a1.font = font
cell_b1 = ws["B1"]
cell_b1.alignment = alignment
cell_b1.font = font
cell_c1 = ws["C1"]
cell_c1.alignment = alignment
cell_c1.font = font
cell_d1 = ws["D1"]
cell_d1.alignment = alignment
cell_d1.font = font
cell_e1 = ws["E1"]
cell_e1.alignment = alignment
cell_e1.font = font
# 엑셀 저장
wb.save("./RPAbasic/crawl/download/" + filename)

'Python' 카테고리의 다른 글
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(정규표현식)(1) (1) | 2022.10.01 |
|---|---|
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(네이버 오픈 API) (1) | 2022.09.30 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(Beautifulsoup)(2) (0) | 2022.09.28 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(Beautifulsoup)(1) (0) | 2022.09.27 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(requests) (1) | 2022.09.26 |
'Python' Related Articles
more




Comments