
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- python수업
- 파이썬알고리즘
- 주피터노트북맷플롯립
- 주피터노트북판다스
- SQLSCOTT
- Python
- sql연습하기
- python데이터분석
- 파이썬차트
- sql따라하기
- sql연습
- 파이썬시각화
- 판다스그래프
- 맷플롯립
- 주피터노트북그래프
- 파이썬데이터분석주피터노트북
- 주피터노트북데이터분석
- 팀플기록
- 판다스데이터분석
- 파이썬데이터분석
- 주피터노트북
- SQL
- SQL수업
- matplotlib
- 파이썬크롤링
- 파이썬수업
- 수업기록
- python알고리즘
- 데이터분석시각화
- 파이썬
Archives
- Today
- Total
IT_developers
Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(1) 본문
RPA(Robotic Process Automation)
- 웹, 윈도우, 어플리케이션(엑셀 등)을 사전에 설정한 시나리오에 따라 자동적으로 작동하여 수작업을 최소화하는 일련의 프로세스
- RPA 사용 소프트웨어
- Uipath, BluePrism, Automation Anywhere, WinAutomation
- RPA 라이브러리
- pyautogui, pyperclip, selenium
크롤링 : 웹 사이트, 하이퍼링크, 데이터 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것
Selenium
- 브라우저 자동화 개념 적용
- webdriver 이용해서 브라우저 조작, 자동으로 일을 시킬 수 있음
- 웹을 테스트하기 위한 프레임워크
- 자바, 파이썬, C#, 자바 스크립트 등 언어들에서 사용 가능
- 소스 가져오기 + 파싱도 가능
- 브라우저도 접근하기 때문에 차단 될 확률도 적어짐
- 요소찾기
- find_element()
- find_elements()
크롬 드라이버 다운로드
[설정] - Chrome 정보 - 버전 확인
크롬 드라이버 검색 : https://chromedriver.chromium.org/downloads
크롬 버전과 일치하는 드라이버 다운로드
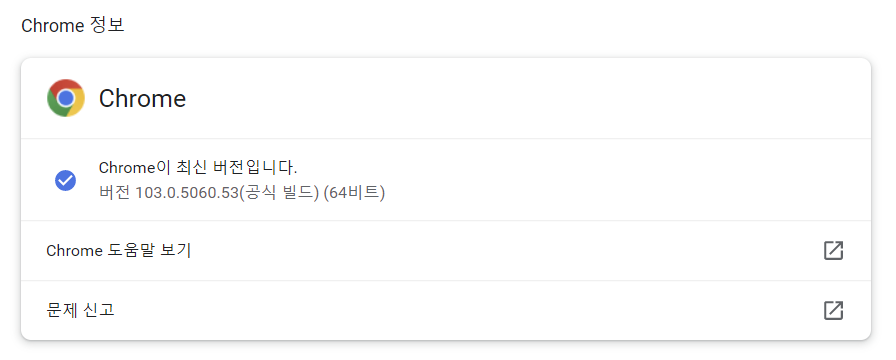

다운로드 - 압축 풀기 - 가상환경으로 이동
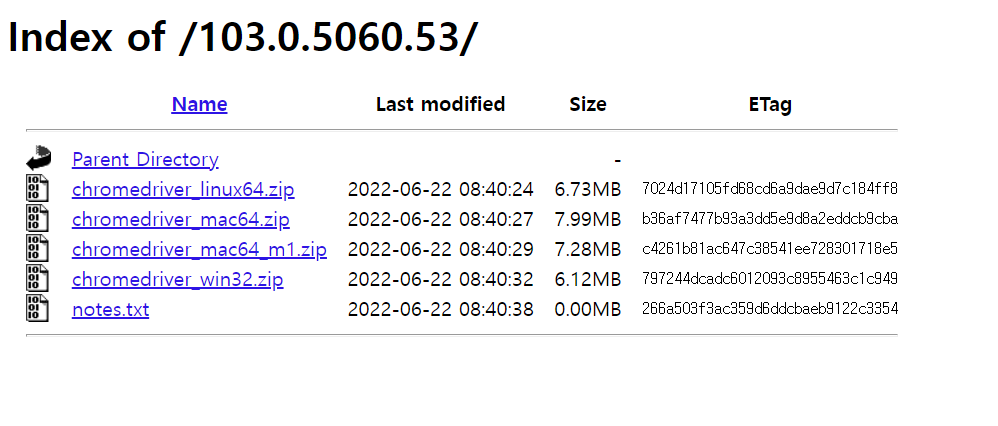
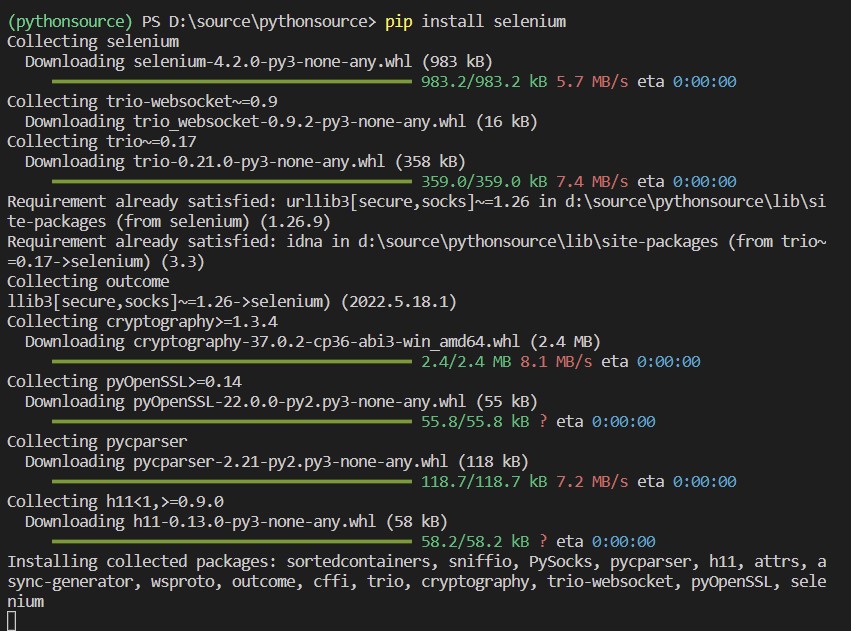
라이브러리 설치 : pip install selenium
RPAbasic\crawl\selenium1 폴더 - 1_webdriver.py
from selenium import webdriver
import time
# . : pythonsource 에 크롬 드라이버 위치
browser = webdriver.Chrome()
# 특정 사이트 연결
# 브라우저 최대화
browser.maximize_window()
time.sleep(3) # 3초 후 닫힘
# 브라우저 닫기
browser.quit()
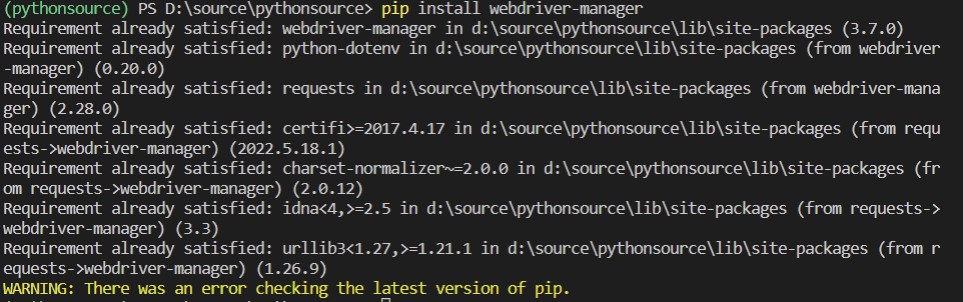
RPAbasic\crawl\selenium1 폴더 - 2_webdriver_manager.py
크롬 드라이버가 안 될 경우
현재 브라우저 버전에 맞는 웹드라이버를 다운로드 받지 않아도 됨
라이브러리 추가 설치 : pip install webdriver-manager
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
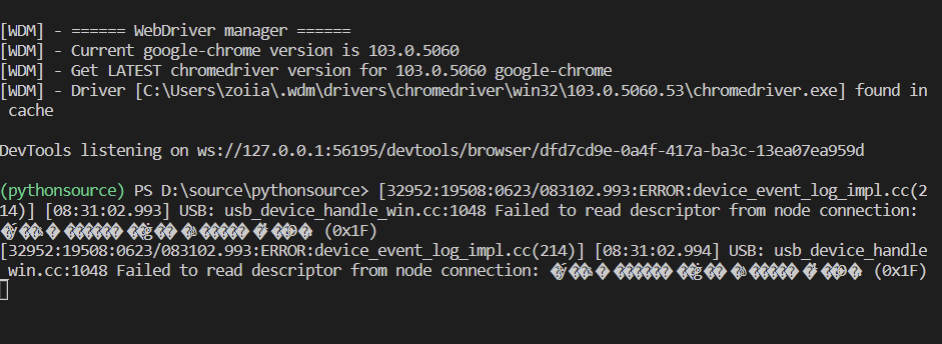
def set_chrome_driver():
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
return driver
if __name__ == "__main__":
driver = set_chrome_driver()
RPAbasic\crawl\selenium1 폴더 - 3_selenium1.py
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.maximize_window()
print(browser.current_url)
print(browser.title) # Daum
# 브라우저 타이틀 안에 Daum이 없다면 오류를 발생시킴
# 테스트 코드에서 오류가 발생하면 이후 코드는 실행 안함
assert "Daum" in browser.title
# 현재 페이지 소스 가져오기
print(browser.page_source)
# 세션 id 가져오기
print(browser.session_id)
# 쿠키 정보 가져오기
print(browser.get_cookies)
time.sleep(3)
browser.quit()
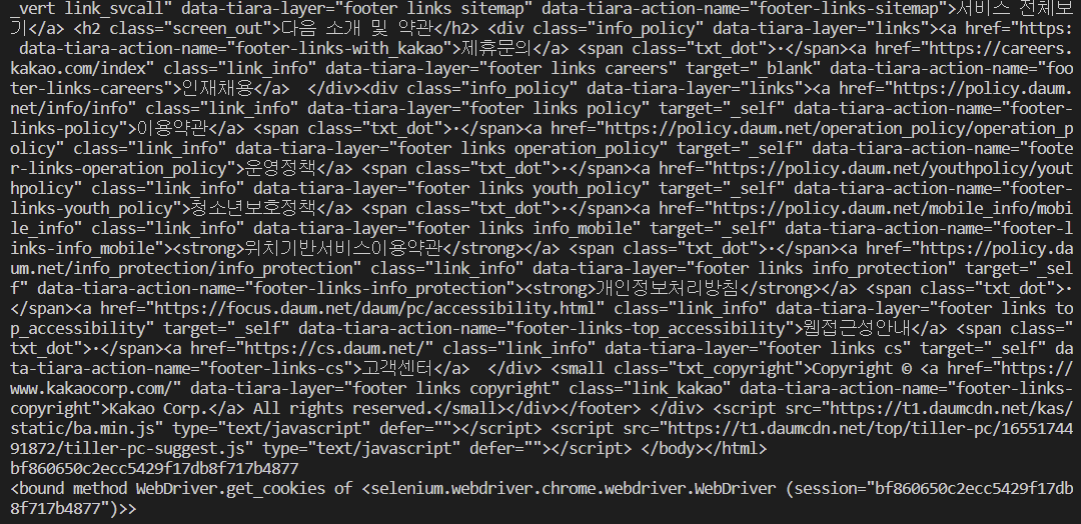
RPAbasic\crawl\selenium1 폴더 - 4_python_org.py
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.maximize_window()
# 타이틀이 Python이 아니면 오류 발생
assert "Python" in browser.title
print("소스 가져오기")
print(browser.page_source)
time.sleep(3)
browser.quit()
RPAbasic\crawl\selenium1 폴더 - 5_find.py
다음에서 아이폰 검색하기
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Chrome()
browser.maximize_window()
# 원하는 요소 찾기
element = browser.find_element(By.NAME, "q")
print(
element
) # <selenium.webdriver.remote.webelement.WebElement (session="44e5c34d77c1aefae5ac98a1c3c32d20", element="e0d596aa-1086-4545-b46d-85929d7ee47f")>
# 검색어 넣기
element.send_keys("아이폰")
element.send_keys(Keys.ENTER)
# 검색 결과 기다리기
time.sleep(1)
# 검색 결과가 뜨고 난뒤 뒤로 가기
browser.back()
time.sleep(3)
browser.quit()
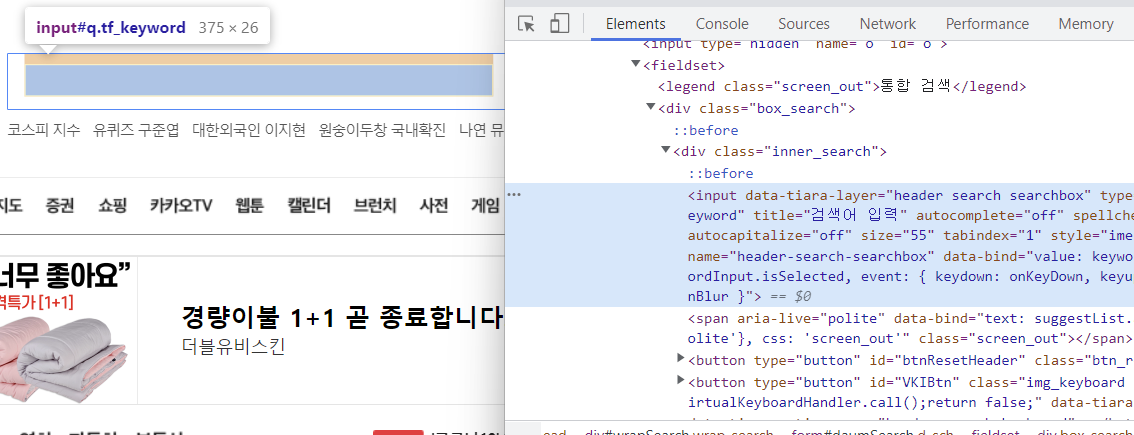

RPAbasic\crawl\selenium1 폴더 - 5_find2.py
파이썬 사이트에서 python 검색 후 결과 타이틀 가지고 오기
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
from bs4 import BeautifulSoup
# 파이썬 사이트 들어갈 수 있는 코드 작성
browser = webdriver.Chrome()
# 화면 최대화
browser.maximize_window()
# 사이트 검색 창 찾기
element = browser.find_element(By.ID, "id-search-field")
# 검색 창 초기화(글자가 남아있을 수 있으므로)
element.clear()
# 검색어 입력
element.send_keys("python")
# 엔터 입력
element.send_keys(Keys.ENTER)
time.sleep(1)
# 결과 페이지에서 원하는 요소 추출 == 파싱
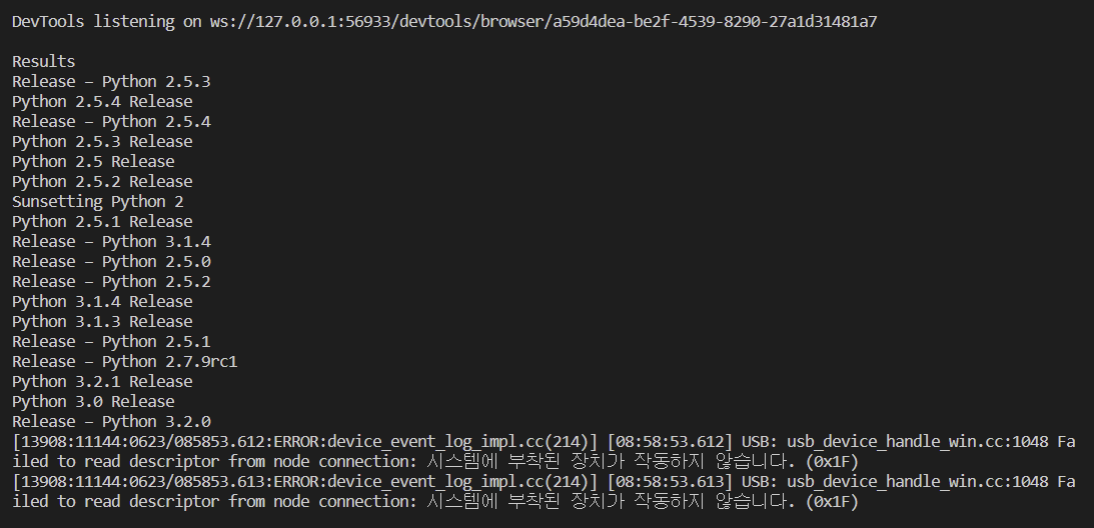
titles = browser.find_elements(By.TAG_NAME, "h3")
for title in titles:
print(title.text)
# BeautifulSoup 이용하는 방식
res = BeautifulSoup(browser.page_source, "lxml")
titles = res.find_all("h3")
for title in titles:
print(title.get_text())
time.sleep(3)
# 화면 닫기
browser.quit()

'Python' 카테고리의 다른 글
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(3) (1) | 2022.10.05 |
|---|---|
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(2) (0) | 2022.10.04 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(정규표현식)(2) (0) | 2022.10.02 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(정규표현식)(1) (1) | 2022.10.01 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(네이버 오픈 API) (1) | 2022.09.30 |
'Python' Related Articles
more




Comments