
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 주피터노트북데이터분석
- python데이터분석
- SQL수업
- python수업
- 파이썬시각화
- 주피터노트북그래프
- 파이썬크롤링
- 파이썬
- 파이썬알고리즘
- python알고리즘
- 파이썬데이터분석
- 맷플롯립
- SQLSCOTT
- 파이썬수업
- 판다스그래프
- SQL
- 데이터분석시각화
- 주피터노트북판다스
- 주피터노트북
- 주피터노트북맷플롯립
- 수업기록
- 파이썬데이터분석주피터노트북
- matplotlib
- Python
- sql연습
- sql따라하기
- sql연습하기
- 판다스데이터분석
- 파이썬차트
- 팀플기록
Archives
- Today
- Total
IT_developers
Python RPA(업무자동화) 개념 및 실습 - 크롤링(정규표현식)(2) 본문
정규 표현식
- 특정한 패턴과 일치하는 문자열을 검색, 치환, 제거하는 기능
파이썬 정규표현식 생성 - re모듈
- 메소드
- match() : 문자열 처음부터 정규식과 매칭되는 패턴 찾아서 리턴
- search() : 문자열 전체를 검색해서 정규식과 매칭되는 패턴 찾아서 리턴
- findall() : 정규식과 일치하는 모든 문자열을 찾아 리스트로 반환
- finditer() : 정규식과 일치하는 모든 문자열을 찾아 iterator 객체로 반환
- split() : 정규식을 기준으로 문자열 분리 후 리스트로 반환
- re.sub(패턴, 바꿀문자열, 원본문자열) : 찾아서 바꾸기
- 패턴 [ ] : [ ] 안에 있는 일치하는 문자가 있으면 매치한다
- Dot(.) : 모든 문자를 의미
- ? : 최소 0 ~ 최대 1 반복
- 반복(*) : 바로 앞에 있는 문자가 반복 횟수가 0~무한대로 반복
- 반복(+) : 바로 앞에 있는 문자가 반복 횟수가 1~무한대로 반복
- {n} : n만큼 반복
- {n,m} : 최소 n, 최대 m 반복
- [ - ] : 사이의 범위를 의미
- [ ^ ] : 포함하지 않음
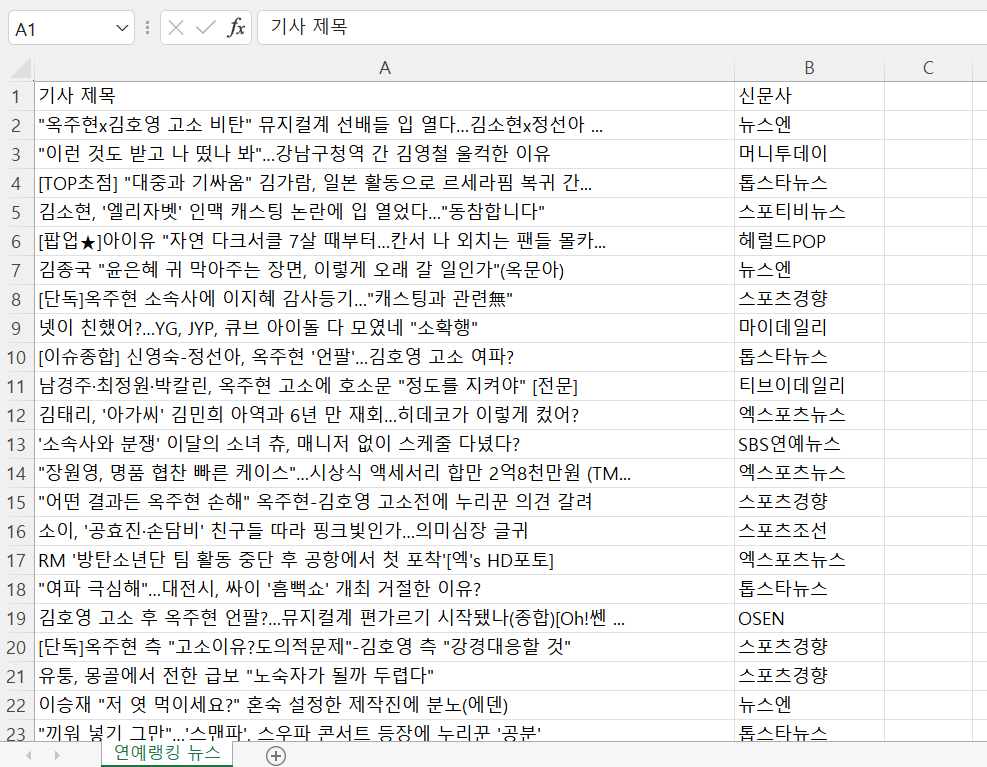
RPAbasic\regex 폴더 - 1_실습_ranking1.py
연예 랭킹 뉴스 추출, 날짜 지우기 + 엑셀 저장
- 시트명 : 연예랭킹뉴스
- 제목, 기사제공자 1~50위
- 날짜 지우기
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
from datetime import datetime
import re
# 엑셀 작업
# 엑셀 파일 생성
wb = Workbook()
# 기본 시트 활성화
ws = wb.active
# 시트명 새로 지정
ws.title = "연예랭킹 뉴스"
ws.column_dimensions["A"].width = 70
ws.column_dimensions["B"].width = 15
# 제목행 지정
ws.append(["기사 제목", "신문사"])
soup = BeautifulSoup(res.text, "lxml")
# 1~5위 가져오기(타이틀, 기사작성자)
top5_list = soup.select("div.mduSubjectList > div")
# 6~50위 가져오기
top45_list = soup.select("#postRankSubject li")
for idx, news in enumerate(top5_list, 1):
# 타이틀 == 자손 태그로 끌기
title = news.select_one("a strong").get_text()
# 신문사(신문사 날짜) - 한글, 영문 문자만 찾기 (마이데일리 2022-06-22)
media_date = news.select_one("span.medium").get_text()
# re.sub() 날짜를 공백으로 바꾸기
pattern = re.compile("[\d-]+") # 숫자와 - 찾기
media = re.sub(pattern, "", media_date)
print(f"{idx} : {title} - {media}")
# split() ==> 결과가 리스트로 뜸['마이데일리','2022-06-22']
media = pattern.split(media_date)
print(f"{idx} : {title} - {media[0]}")
ws.append([title, media])
# re.sub(), split() : 둘 중 한가지만 실행
for idx, news in enumerate(top45_list, 6):
# 타이틀
title = news.select_one("a").get_text()
# 신문사
media = news.select_one("span.medium").get_text()
print(f"{idx} : {title} - {media}")
ws.append([title, media])
# 파일명 nate_오늘날짜.xlsx
today = datetime.now().strftime("%y%m%d")
filename = f"nate_{today}.xlsx"
# 엑셀 저장
wb.save("./RPAbasic/crawl/download/" + filename)

RPAbasic\regex 폴더 - 2_실습_openapi1.py
네이버 오픈API
- 키보드 검색
- 제품명 </b> 태그 지우기
- 엑셀 저장
import requests
from openpyxl import Workbook
from datetime import datetime
import re
# 엑셀 파일 생성
wb = Workbook()
# 기본 시트 활성화
ws = wb.active
# 시트명 새로 지정
ws.title = "키보드 1000"
ws.column_dimensions["B"].width = 60
ws.column_dimensions["C"].width = 80
ws.column_dimensions["D"].width = 15
ws.append(["순위", "상품명", "상세주소 url", "최저가"])
client_id = "ITricAb_moCNCZRXqDKt"
client_secret = "i1dMkiMcjU"
headers = {"X-Naver-Client-Id": client_id, "X-Naver-Client-Secret": client_secret}
start, num = 1, 0
for idx in range(10):
start_num = start + (idx * 100)
url = (
+ str(start_num)
)
print(url)
res = requests.get(url, headers=headers)
data = res.json()
for item in data["items"]:
num += 1
# 제품명에 태그 들어간 부분 제거하고 저장
# <b> 내용 </b>, <h1> 아이폰</h1>
title = re.sub("<.+?>", "", item["title"])
print(title, item["link"], item["lprice"])
ws.append([num, title, item["link"], item["lprice"]])
# 파일명 navershop_오늘날짜.xlsx
today = datetime.now().strftime("%y%m%d")
filename = f"navershop_{today}.xlsx"
# 엑셀 저장
wb.save("./RPAbasic/crawl/download/" + filename)

RPAbasic\regex 폴더 - regex6.py
import re
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text, "lxml")
# h 태그로 시작하는 모든 태그 찾기
# h1 ~ h6
print(soup.find_all(re.compile("h\d"))) # h태그 뒤에 숫자

# 이미지 파일을 가져오기 - 1.jpg, ex.jpg,
#.+\.jpg ==> . (모든문자) + (무조건하나는와야함) \.(확장자구별 점)
print(soup.find_all("img", attrs={"src": re.compile(".+\.jpg")})) # 확장자가 jpg 끝나는
print(soup.find_all("img", attrs={"src": re.compile(".+\.jpg|png")})) #jpg이나 png

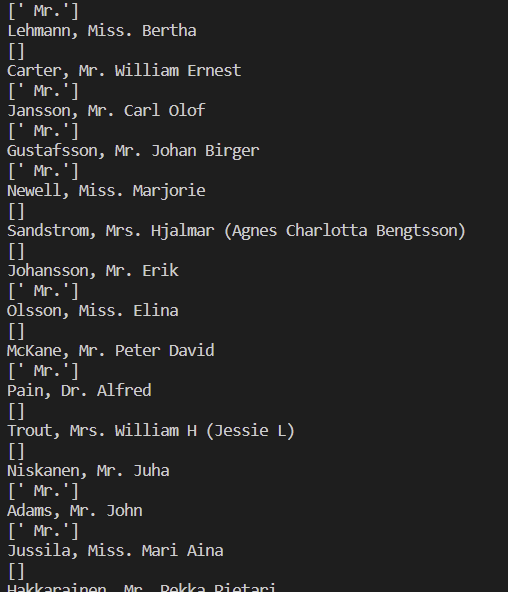
RPAbasic\regex 폴더 - regex7.py
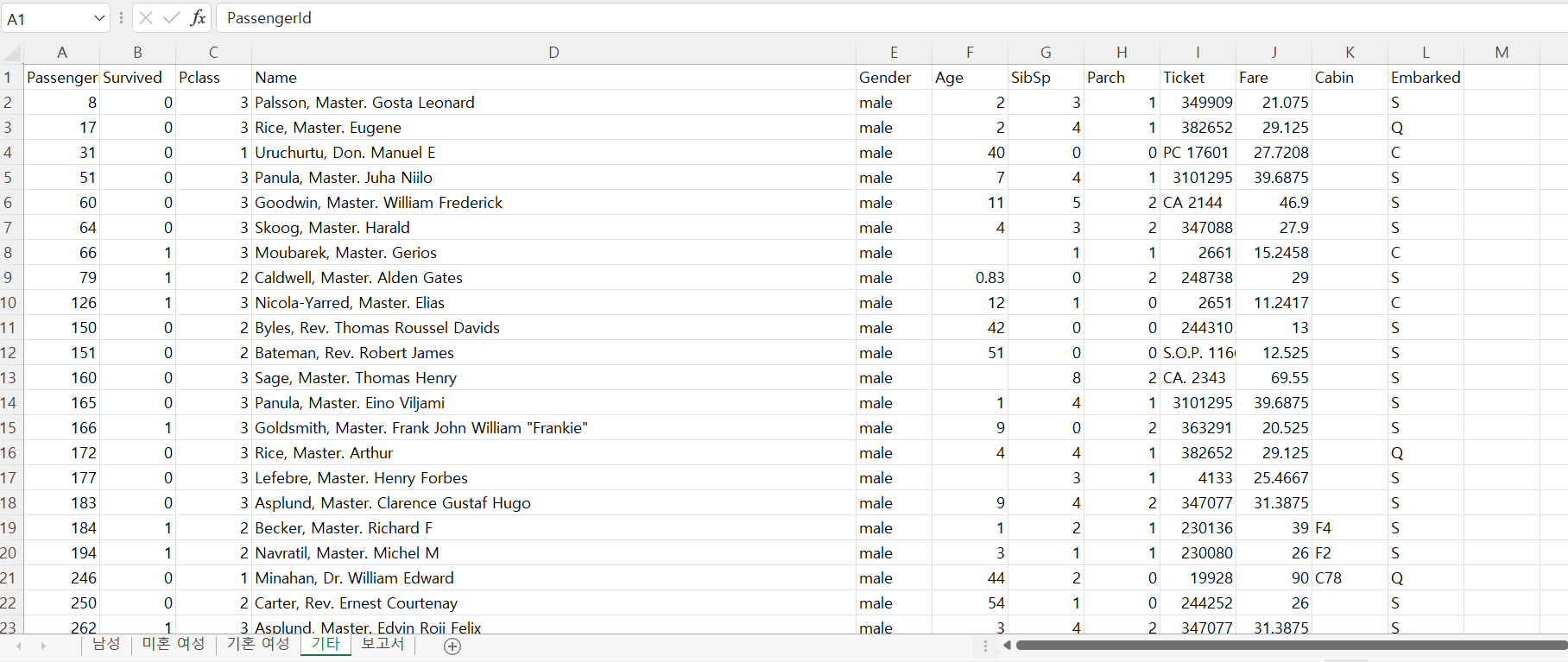
train.xlsx 읽어서 정규식 적용- 타이타닉 탑습자 명단

from openpyxl import load_workbook
import re
path = "./RPAbasic/crawl/download/"
wb = load_workbook(path + "train.xlsx")
ws = wb.active
# Name 출력 : 4번째 열.
for each_row in ws.rows:
print(each_row[3].value)
# 전체 성별을 가지고 올때
pattern = re.compile(" [A-Za-z]+\.")
# Name 출력 : Braund, Mr. Owen Harris ==> Mr.부분 찾는 패턴
for each_row in ws.rows:
print(each_row[3].value)
print(pattern.findall(each_row[3].value))
# print(
# pattern.search(each_row[3].value).group()
# ) # AttributeError: 'NoneType' object has no attribute 'group'

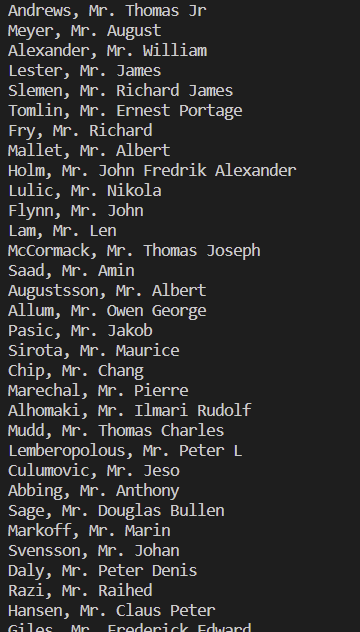
# 남자만 알고 싶을때
pattern = re.compile(" Mr\.")
for each_row in ws.rows:
print(each_row[3].value)
print(pattern.findall(each_row[3].value)) # 찾은게 없다면 빈 괄호
if len(pattern.findall(each_row[3].value)) > 0:
print(each_row[3].value)
wb.close()
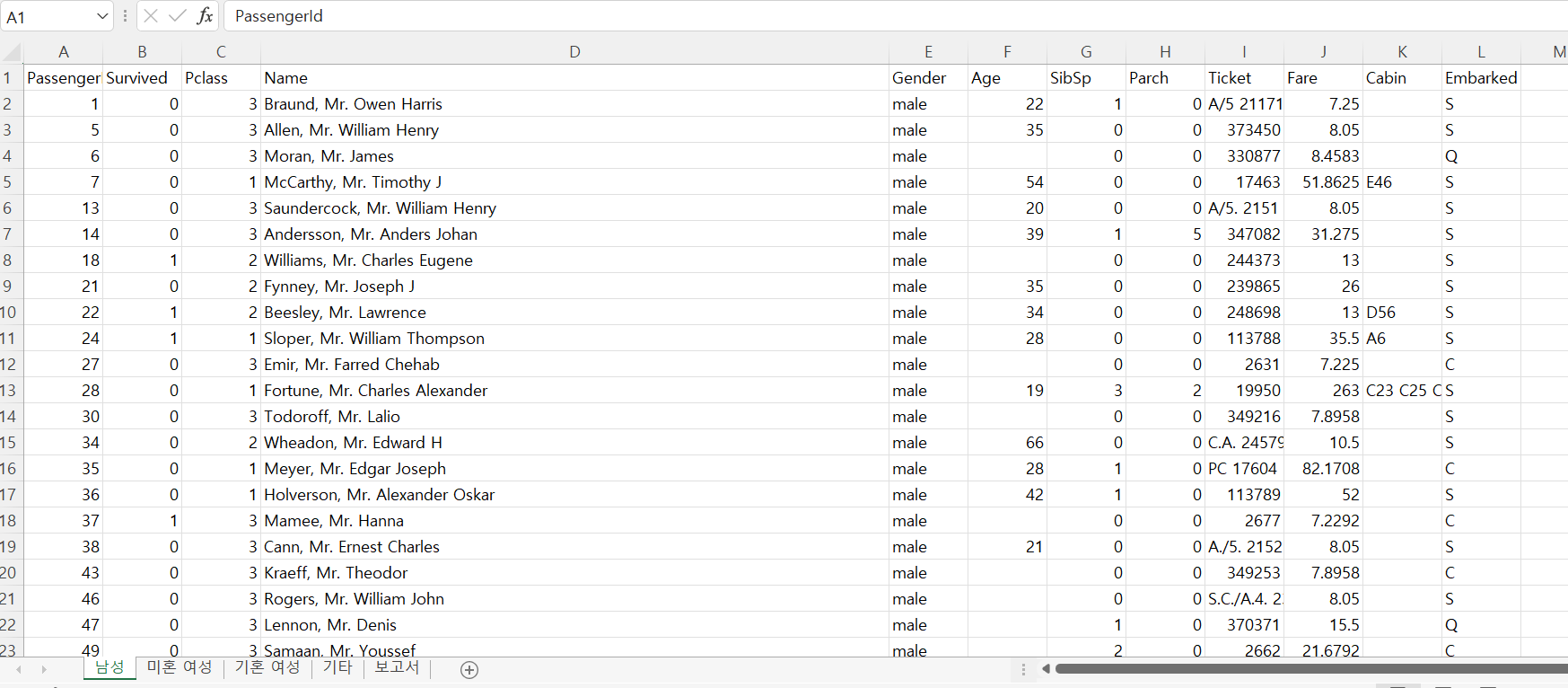
RPAbasic\regex 폴더 - regex8.py
train.xlsx 읽기 - 타이타닉 탑습자 명단
- 전체 데이터를 읽어서 성별에 따른 고객명단 만들기
- 새로운 엑셀파일(train_gender.xlsx) 작성
- 남성(Mr.), 미혼여성(Miss.), 기혼 여성(Mrs.), 기타
- 추가 생존률 보고서 시트
from openpyxl import load_workbook
import re
from openpyxl import Workbook
path = "./RPAbasic/crawl/download/"
wb = load_workbook(path + "train.xlsx")
ws = wb.active
# 엑셀 파일 생성
work_book = Workbook()
# 첫번째 시트 생성
work_sheet_man = work_book.active
work_sheet_man.title = "남성"
work_sheet_man.column_dimensions["D"].width = 70
# 두번째 시트 (만들어야함)
work_sheet_solo_women = work_book.create_sheet()
work_sheet_solo_women.title = "미혼 여성"
work_sheet_solo_women.column_dimensions["D"].width = 70
# 세번째 시트 (만들어야함)
work_sheet_married_women = work_book.create_sheet()
work_sheet_married_women.title = "기혼 여성"
work_sheet_married_women.column_dimensions["D"].width = 70
# 네번째 시트 (만들어야함)
work_sheet_others = work_book.create_sheet()
work_sheet_others.title = "기타"
# 다른 방법 : work_sheet_others = work_book.create_sheet(title="기타")
work_sheet_others.column_dimensions["D"].width = 70
# 5번째 시트 생성(보고서)
# 분류 생존자수 사망자수 생존률
# 남성 48 12 80%
# 미혼여성 ##
# 기혼여성 ##
# 기타 ##
# 5번째 시트 생성
work_sheet_report = work_book.create_sheet(title="보고서")
work_sheet_report.append(["분류", "생존자수", "사망자수", "생존률"])
pattern = re.compile(" [A-Za-z]+\.")
# 생존자수, 사망자 수 카운트 할 변수 선언
man_survived, man_unservived = 0, 0
solo_survived, solo_unservived = 0, 0
married_survived, married_unservived = 0, 0
others_survived, others_unservived = 0, 0
# 남성(Mr.), 미혼여성(Miss.), 기혼 여성(Mrs.), 기타 구분
pattern = re.compile("[A-Za-z]+\.")
for each_row in ws.iter_rows():
# 첫번째 행인 경우 제목행이기 때문에 모든 sheet에 붙여넣기
title_list = []
if each_row[0].row == 1:
# for col in each_row:
# title_list.append(col.value)
# print(title_list)
# work_sheet_man.append(title_list)
# work_sheet_solo_women.append(title_list)
# work_sheet_married_women.append(title_list)
# work_sheet_others.append(title_list)
# 위의 작업을 한번에 실행. List Comprehension 방법
work_sheet_man.append(col.value for col in each_row)
work_sheet_solo_women.append(col.value for col in each_row)
work_sheet_married_women.append(col.value for col in each_row)
work_sheet_others.append(col.value for col in each_row)
# 두번째 ~ 마지막행 까지는 이름 읽어서 각 성별에 맞춰서 시트에 붙여넣기
else:
# 패턴을 찾는 경우 찾은 문자열 리턴, 못찾으면 비어있는 리스트 [] 리턴
data = pattern.findall(each_row[3].value)
if len(data) > 0:
if data[0] == " Mr.": # 앞에 공백
work_sheet_man.append(col.value for col in each_row)
if each_row[1].value == 1: # 생존자
man_survived += 1
else:
man_unservived += 1
elif data[0] == " Miss.": # 앞에 공백
work_sheet_solo_women.append(col.value for col in each_row)
if each_row[1].value == 1: # 생존자
solo_survived += 1
else:
solo_unservived += 1
elif data[0] == " Mrs.": # 앞에 공백
work_sheet_married_women.append(col.value for col in each_row)
if each_row[1].value == 1: # 생존자
married_survived += 1
else:
married_unservived += 1
else:
work_sheet_others.append(col.value for col in each_row)
if each_row[1].value == 1: # 생존자
others_survived += 1
else:
others_unservived += 1
# 보고서 작성
# 남성 생존율
man_survived_rate = "%.2f%%" % (man_survived / (man_survived + man_unservived) * 100)
# 미혼 여성 생존율
solo_survived_rate = "%.2f%%" % (
solo_survived / (solo_survived + solo_unservived) * 100
)
# 기혼 생존율
married_survived_rate = "%.2f%%" % (
married_survived / (married_survived + married_unservived) * 100
)
# 기타 생존율
others_survived_rate = "%.2f%%" % (
others_survived / (others_survived + others_unservived) * 100
)
work_sheet_report.append(["남성", man_survived, man_unservived, man_survived_rate])
work_sheet_report.append(["미혼 여성", solo_survived, solo_unservived, solo_survived_rate])
work_sheet_report.append(
["기혼 여성", married_survived, married_unservived, married_survived_rate]
)
work_sheet_report.append(
["기타", others_survived, others_unservived, others_survived_rate]
)
# 새로운 엑셀 파일에 저장
work_book.save(path + "train_gender.xlsx")
# 원본 엑셀 닫기
wb.close()
# 새로운 엑셀 파일 닫기
work_book.close()

'Python' 카테고리의 다른 글
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(2) (0) | 2022.10.04 |
|---|---|
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(1) (0) | 2022.10.03 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(정규표현식)(1) (1) | 2022.10.01 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(네이버 오픈 API) (1) | 2022.09.30 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(Beautifulsoup)(3) (1) | 2022.09.29 |
'Python' Related Articles
more




Comments