
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- sql연습하기
- 주피터노트북맷플롯립
- 주피터노트북데이터분석
- SQLSCOTT
- 주피터노트북
- SQL수업
- 판다스그래프
- 데이터분석시각화
- 파이썬데이터분석
- 파이썬
- 팀플기록
- 판다스데이터분석
- 파이썬시각화
- 맷플롯립
- 파이썬수업
- 주피터노트북판다스
- python데이터분석
- 주피터노트북그래프
- 파이썬데이터분석주피터노트북
- 파이썬알고리즘
- sql따라하기
- sql연습
- python수업
- Python
- SQL
- 파이썬차트
- python알고리즘
- 파이썬크롤링
- 수업기록
- matplotlib
- Today
- Total
목록주피터노트북판다스서브셋 (4)
IT_developers
 Python 데이터 분석(주피터노트북) - Pandas(Subset 실습)
Python 데이터 분석(주피터노트북) - Pandas(Subset 실습)
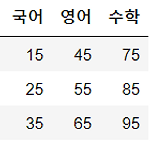
[실습] student_df 1) loc 사용해서 2번행 가져오기 2) loc 사용해서 1번 행의 수학 점수 가져오기 3) loc 사용해서 전체행의 수학 점수 가져오기 4) 특정 행 조회 [실습] month_df 1) loc 사용해서 2월 행 가져오기 2) loc 사용해서 전체 행의 영어 컬럼 가져오기 3) loc 사용해서 2월 ~ 3월 행의 전체 컬럼 가져오기 4) iloc 사용해서 2월 ~ 3월 행의 전체 컬럼 가져오기 [실습] Subset 1. 라이브러리 로드 2. sample.xlsd 1) 데이터 프레임 생성 2) 앞 쪽의 5행 조회 3) 뒤 쪽의 3행 조회 4) 금월 컬럼에서 값이 큰 3개 행 조회 5) 전월 컬럼에서 값이 가장 작은 5개 행 조회 6) 총 판매수량이 250보다 큰 대리점 추출 ..
 Python 데이터 분석(주피터노트북) - Pandas(Subset-row and columns)(3)
Python 데이터 분석(주피터노트북) - Pandas(Subset-row and columns)(3)
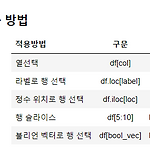
rows, columns 기준 loc[ ] 5 또는 a 와 같은 단일 라벨 ['a','b','c']와 같은 리스트나 라벨의 배열 a:f 와 같이 라벨이 있는 처음과 끝의 범위를 포함하는 슬라이스 객체 [True, False, True]와 같이 슬라이싱할 축과 같은 길이의 불리언 배열 호출하는 시리즈나 데이터 프레임을 인수로 가지는 호출 함수 iloc[ ] 정수 [4,3,0] 과 같은 리스트나 정수들의 배열 1:7 과 같은 정숫값을 가지는 슬라이스 객체 불리언 배열 호출하는 시리즈나 데이터프레임을 인수로 가지는 호출 함수 1) df.iloc[ ] : 행, 열 모두 position 값을 이용(integer 값) 2) df.loc[ ] : 행, 열의 label 값을 이용하거나, boolean 이용/ 마지막 값..
 Python 데이터 분석(주피터노트북) - Pandas(Subset-columns)(2)
Python 데이터 분석(주피터노트북) - Pandas(Subset-columns)(2)
Subset - columns 라이브러리 import pandas as pd import numpy as np [실습] student_df
 Python 데이터 분석(주피터노트북) - Pandas(Subset-row)(1)
Python 데이터 분석(주피터노트북) - Pandas(Subset-row)(1)
Subset - row 라이브러리 import pandas as pd import numpy as np 데이터 생성 1) head() / tail() 2) sample() : 임의 값 가지고 오기 3) nlargest() / nsmallest() : 최대값, 최소값 n 값은 지정 가능 4) drop_duplicates() : 중복행 제거 duplicated() : 중복된 행이 있는지 True/False로 알려줌 df.drop_duplicates( subset: Union[Hashable, Sequence[Hashable], NoneType] = None, keep: Union[str, bool] = 'first', inplace: bool = False, ignore_index: bool = False,..