
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Python
- matplotlib
- 주피터노트북
- sql연습하기
- 데이터분석시각화
- 파이썬크롤링
- python알고리즘
- 주피터노트북데이터분석
- 파이썬데이터분석
- sql따라하기
- 주피터노트북그래프
- 파이썬데이터분석주피터노트북
- 주피터노트북맷플롯립
- 파이썬시각화
- 팀플기록
- SQLSCOTT
- python데이터분석
- 판다스그래프
- python수업
- SQL수업
- SQL
- sql연습
- 수업기록
- 판다스데이터분석
- 주피터노트북판다스
- 파이썬
- 파이썬수업
- 맷플롯립
- 파이썬차트
- 파이썬알고리즘
- Today
- Total
IT_developers
Python 데이터 분석(주피터노트북) - Pandas(실습-전체 복습 퀴즈) 본문
라이브러리
- import pandas as pd
- import numpy as np
[퀴즈1]
[문제] 다음은 대한민국 영화중에서 관객 수가 가장 많은 상위 10개의 데이터입니다.
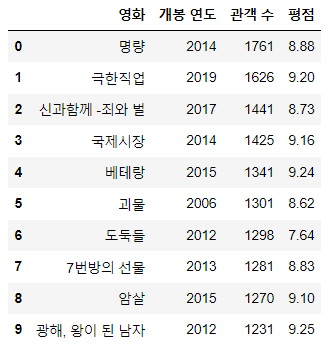
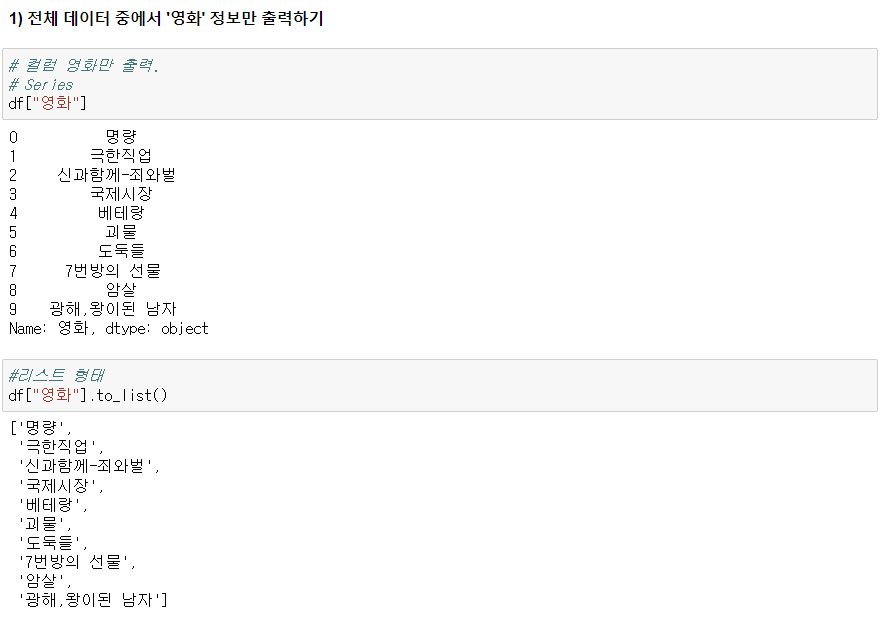
1) 전체 데이터 중에서 '영화' 정보만 출력
2) 전체 데이터 중에서 '영화','평점' 정보 출력
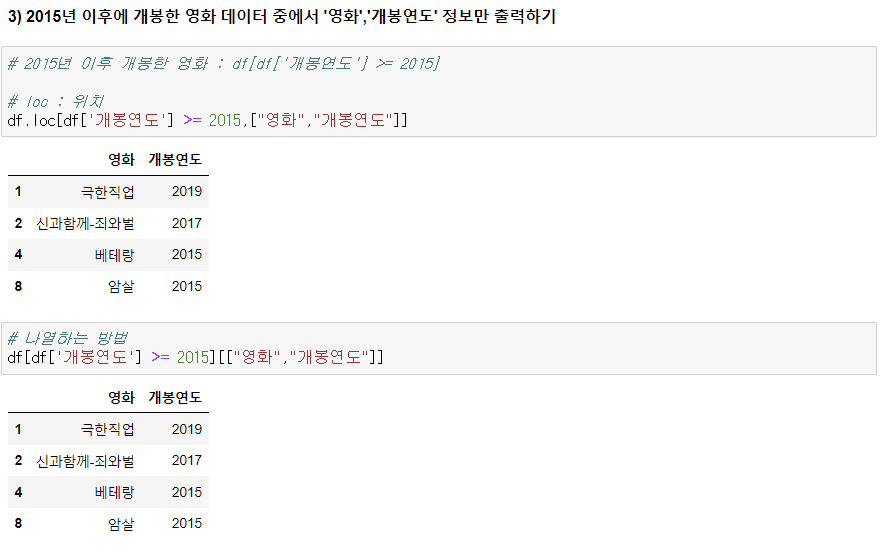
3) 2015년 이후에 개봉한 영화 데이터 중에서 '영화', '개봉연도' 정보만 출력
4) 주어진 계산식을 참고하여 '추천점수' 컬럼 추가
5) 전체 데이터를 '개봉 연도' 기준 내림차순으로 출력





[퀴즈2]

1) 현재 생성된 데이트 프레임의 전체 정보 출력
2) 타입변경



[퀴즈3]

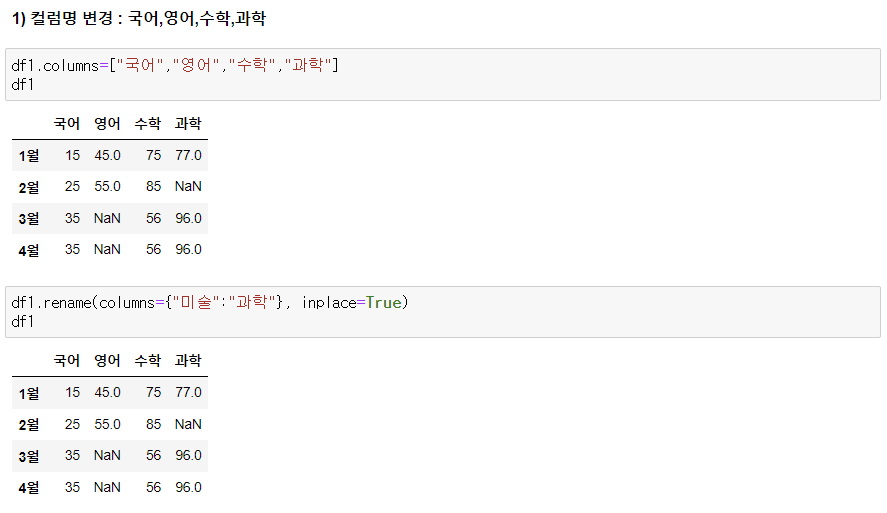
1) 컬럼명 변경 : 국어, 영어, 수학, 과학
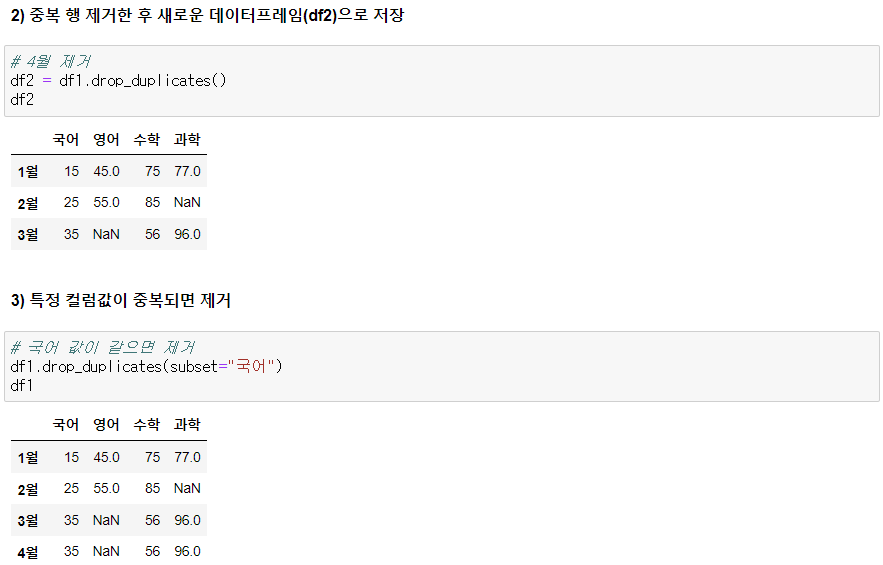
2) 중복 행 제거한 후 새로운 데이터 프레임 (df2)으로 저장
3) 특정 컬럼값이 중복되면 저게

[퀴즈4]
1) data/shop/olist_customers_dataset.csv 파일 dataframe 생성(데이터 프레임 변수 이름 customer로 지정)
2) 처음 5개 행 확인
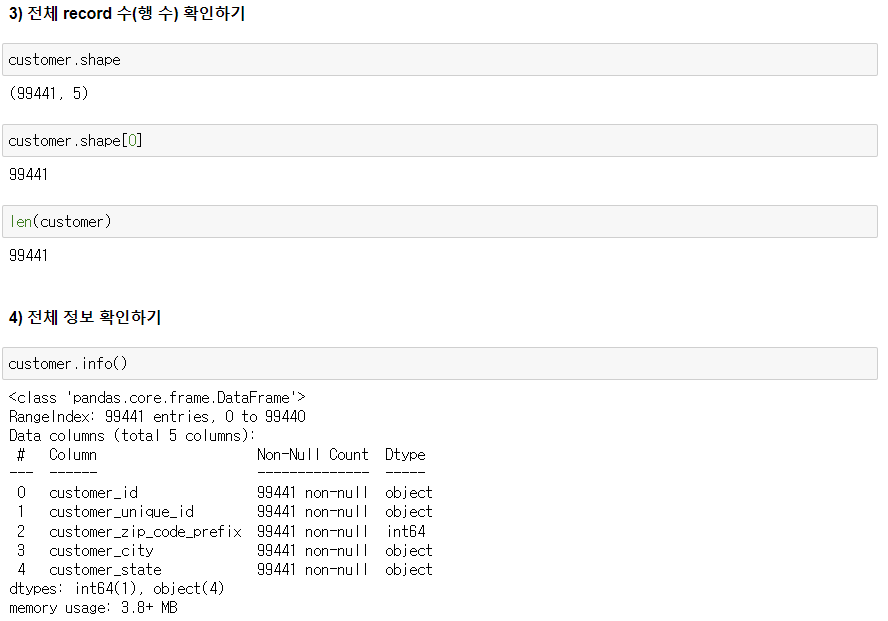
3) 전체 record수 (행 수) 확인
4) 전체 정보 확인하기
5) 전체 컬럼명 확인
6) 인덱스 확인
7) 기술통계요약 정보 확인
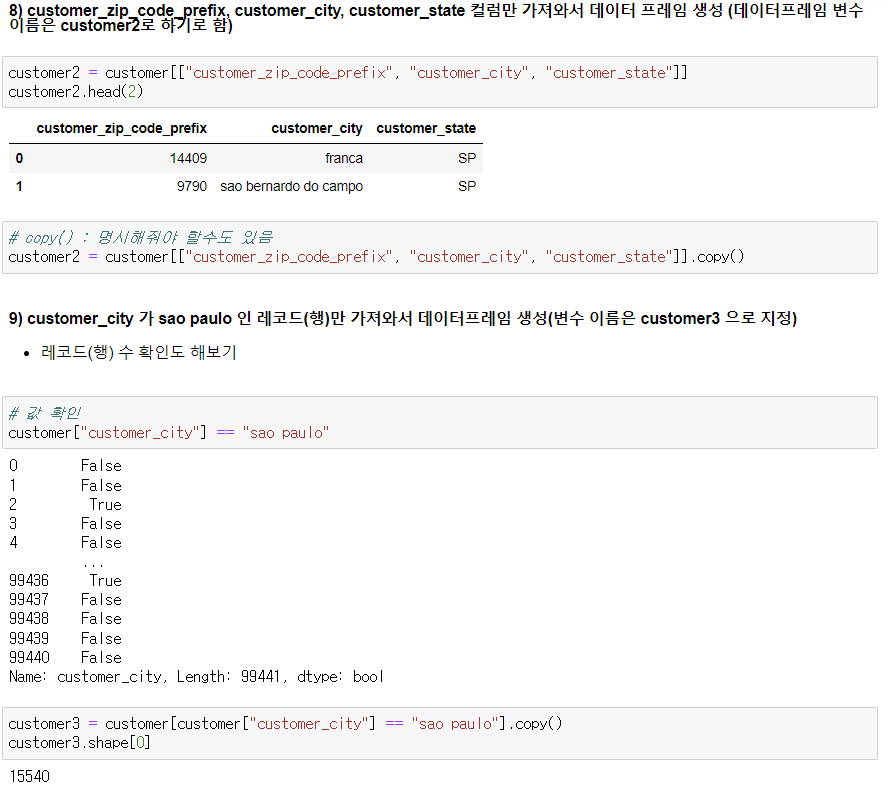
8) customer_zip_code_prefix, customer_city, customer_state 컬럼만 가져와서 데이터 프레임 생성(데이터 프레임 변수 이름은 customer2로 하기로 함)
9) customer_city가 sao paulo 인 레코드(행)만 가져와서 데이터프레임 생성(변수 이름은 customer3 으로 지정)
- 레코드(행) 수 확인도 해보기
10) customer2에서 도시별 고유 값들의 수를 확인하기
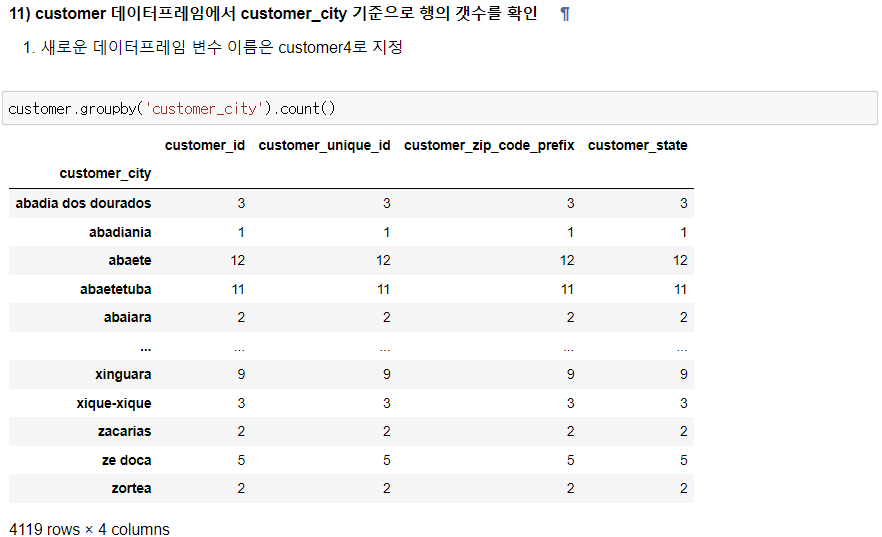
11) customer 데이터 프레임에서 customer_city 기준으로 행의 갯수를 확인
- 새로운 데이터프레임 변수 이름은 customer4로 지정
12) customer4에서 가장 레코드(행)의 수가 많은 customer_city를 확인
- customer4의 customer_id를 기준으로 정렬하고, 가장 상단의 한 행만 출력
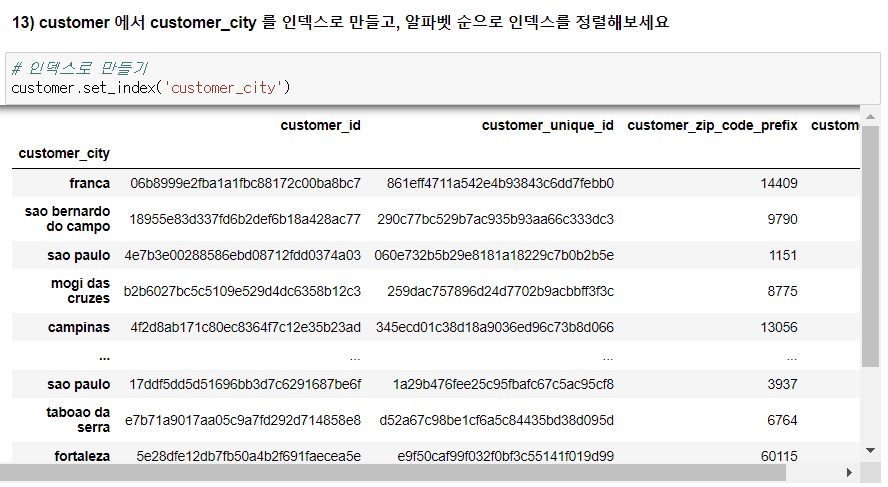
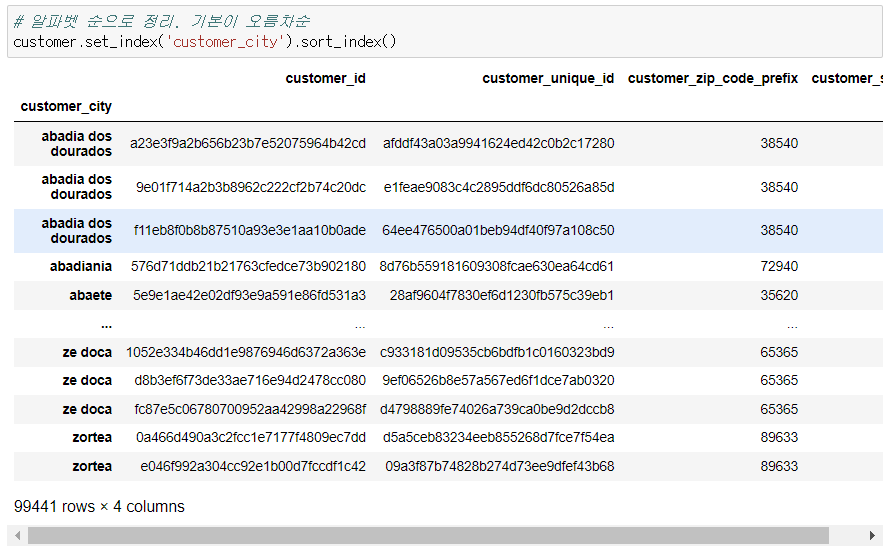
13) customerdptj customer_city를 인덱스로 만들고, 알파벳 순으로 인덱스를 정렬
14) customer2에서 customer_state 기준으로 행의 갯수를 확인
- value_counts()
15) customer2에서 customer_state 갯수 확인
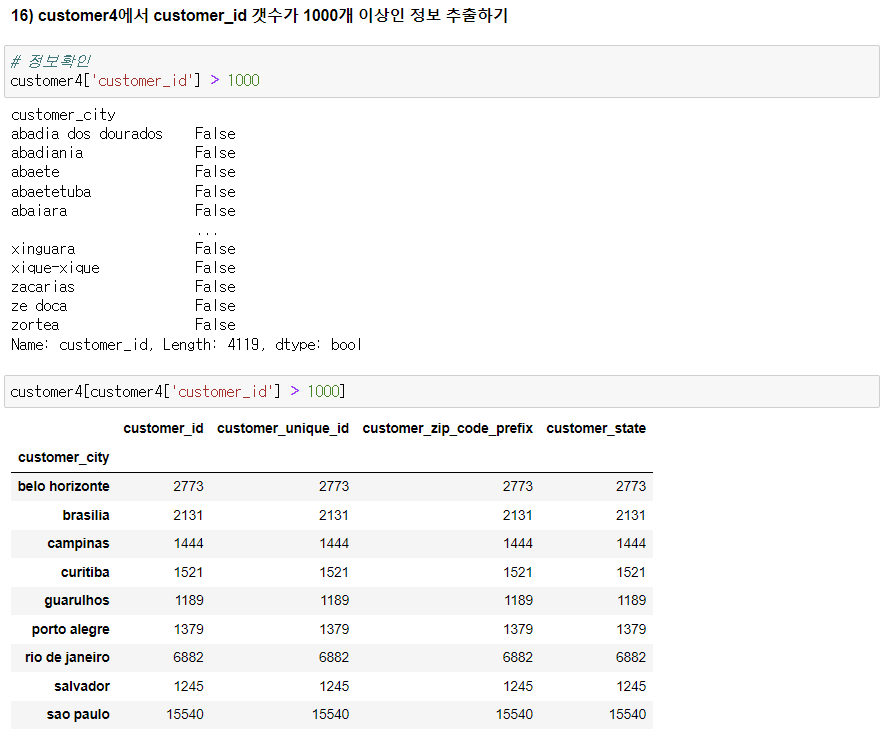
16) customer4에서 customer_id 갯수가 1000개 이상인 정보 추출
17) customer4에서 customer_id 갯수가 1000개 이상인 customer_city 이름 확인
18) customer에서 결측치가 각 컬럼에 있는지 확인
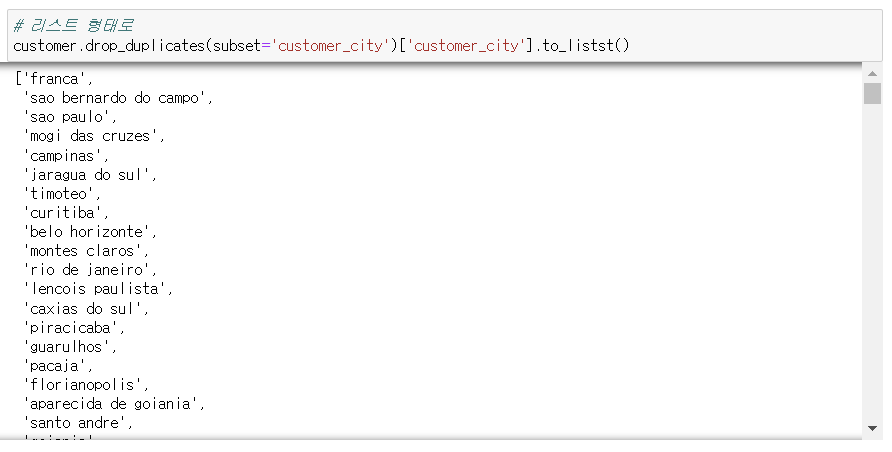
19) customer에서 중복된 customer_city를 가진 행을 삭제한 후, customer_city 이름만 출력









[퀴즈5]
1) data/covid/04-01-2020.csv 파일 dataframe 생성 (데이터프레임 변수 이름은 covid_df 로 지정)
2) covid_df 에서 중복된 Country_Region 각각에 대해 Confirmed 를 모두 더한 값을 컬럼으로 갖는 데이터프레임을 피봇테이블 작성
3) covid_df 에서 중복된 Country_Region 각각에 대해 Confirmed 를 모두 더한 값을 컬럼으로 갖는 데이터프레임을 피봇테이블로 만들고, 총 값을 'Total' 을 인덱스 값으로 하는 record 로 추가
- 결측치는 0으로 처리


'Python' 카테고리의 다른 글
| Python 데이터 분석(주피터노트북) - Matplotlib(축) (0) | 2022.11.11 |
|---|---|
| Python 데이터 분석(주피터노트북) - Matplotlib(차트 기본) (0) | 2022.11.11 |
| Python 데이터 분석(주피터노트북) - Pandas(time_series) (0) | 2022.11.09 |
| Python 데이터 분석(주피터노트북) - Pandas(기타-크롤링) (0) | 2022.11.08 |
| Python 데이터 분석(주피터노트북) - Pandas(텍스트 데이터 가공) (0) | 2022.11.07 |



