
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- SQL
- 주피터노트북
- 파이썬차트
- Python
- 주피터노트북데이터분석
- SQL수업
- sql따라하기
- 주피터노트북맷플롯립
- 주피터노트북판다스
- 주피터노트북그래프
- matplotlib
- sql연습
- 파이썬알고리즘
- 수업기록
- sql연습하기
- python데이터분석
- 판다스그래프
- 파이썬수업
- 파이썬
- 판다스데이터분석
- 팀플기록
- python수업
- 파이썬크롤링
- 파이썬시각화
- 맷플롯립
- 파이썬데이터분석
- 데이터분석시각화
- python알고리즘
- 파이썬데이터분석주피터노트북
- SQLSCOTT
Archives
- Today
- Total
IT_developers
Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(3) 본문
RPA(Robotic Process Automation)
- 웹, 윈도우, 어플리케이션(엑셀 등)을 사전에 설정한 시나리오에 따라 자동적으로 작동하여 수작업을 최소화하는 일련의 프로세스
- RPA 사용 소프트웨어
- Uipath, BluePrism, Automation Anywhere, WinAutomation
- RPA 라이브러리
- pyautogui, pyperclip, selenium
크롤링 : 웹 사이트, 하이퍼링크, 데이터 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것
Selenium
- 브라우저 자동화 개념 적용
- webdriver 이용해서 브라우저 조작, 자동으로 일을 시킬 수 있음
- 웹을 테스트하기 위한 프레임워크
- 자바, 파이썬, C#, 자바 스크립트 등 언어들에서 사용 가능
- 소스 가져오기 + 파싱도 가능
- 브라우저도 접근하기 때문에 차단 될 확률도 적어짐
- 요소찾기
- find_element() : 하나의 요소를 찾을 때
- find_elements() : 여러개의 요소를 찾을 때
- 아이디 값 : find_element(By.ID, "ID 값")
- CSS 선택자 : find_element(By.CSS_SELECTOR, "#선택자 값")
- 클래스 : find_element(By.CLASS_NAME, "NAME 값")
- Xpath : find_element(By.XPATH, '//*[@Xpath 값"]')
- By.NAME, By.CLASS_NAME, By.CSS_SELECTOR, By.ID, By.LINK_TEXT, By.PARTIAL_LINK_TEXT, By.TAG_NAME, By.XPATH
- ActionChain() : 여러 개의 액션을 수행할 경우 차례대로 저장한 후 수행
- 마우스 이동, 마우스 버튼 클릭, key press 등등
RPAbasic\crawl\selenium1 폴더 - 12_iframe1.py
iframe : 하나의 html 페이지에서 다른 html 페이지를 포함
iframe 안에 있는 요소 찾기
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(2)
# iframe 안의 태그 찾기
# iframe 안으로 들어가서 찾아야 함
browser.switch_to.frame("iframeResult")
element = browser.find_element(By.TAG_NAME, "h1")
# frame 전 에러 : NoSuchElementException: Message: no such element: Unable to locate element: {"method":"tag name","selector":"h1"}
print("h1 :", element.text)
# iframe 밖으로 나오기
browser.switch_to.default_content()
# 왼쪽에 있던 요소 찾기
left = browser.find_element(
By.XPATH,
'//*[@id="textareawrapper"]/div/div[6]/div[1]/div/div/div/div[5]/pre[12]/span/span[10]',
)
print(left.text)
time.sleep(3)
browser.quit()


RPAbasic\crawl\selenium1 폴더 - 12_iframe2.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Chrome()
browser.get(
)
browser.maximize_window()
time.sleep(1)
# h1 태그 찾기
h1_element = browser.find_element(
By.XPATH,
'//*[@id="textareawrapper"]/div/div[6]/div[1]/div/div/div/div[5]/pre[5]/span/span[4]',
)
print(h1_element.text)
# iframe 안의 태그 찾기
# iframe 안으로 들어가서 찾아야 함
browser.switch_to.frame("iframeResult")
# 첫번째 라디오 찾은 후 클릭
element = browser.find_element(By.XPATH, '//*[@id="html"]').click()
# 다른 방법 : browser.find_element(By.ID,"html").click
time.sleep(3)
browser.quit()


RPAbasic\crawl\selenium1 폴더 - 13_script1.py
파이썬에서 스크립트 쓰기
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(1)
# 두번째 탭을 연 후에 daum 접속
# 스크립트로 새창 열기
# 현재 페이지는 어디인지 확인
print("1. title {} ".format(browser.title)) # Naver
# 현재 브라우저에 열린 탭 가져오기
tabs = browser.window_handles # tabs[0] : 처음 접속 페이지
browser.switch_to.window(tabs[1]) # 코드 이후론 다음페이지로 이동
print("2. title {} ".format(browser.title))
element = browser.find_element(By.NAME, "q")
element.send_keys("아이폰")
element.send_keys(Keys.ENTER)
time.sleep(1)
# 네이버로 돌아오기
browser.switch_to.window(tabs[0])
time.sleep(3)
browser.quit()
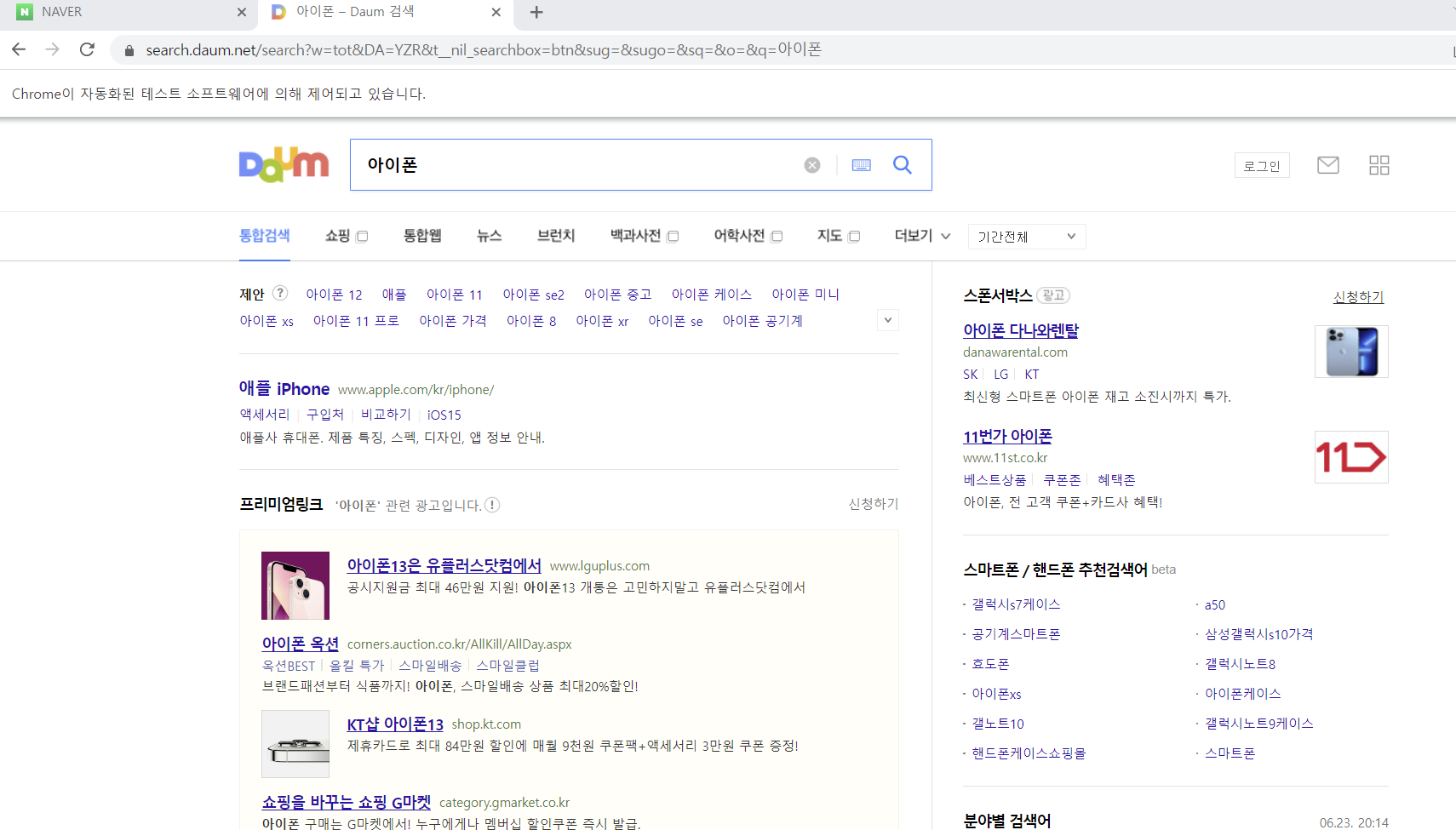

RPAbasic\crawl\selenium1 폴더 - 13_script2.py
전체 스크롤 스크립트 - 네이버에서 검색 한 후 스크롤 하기
browser.execute_script("window.scrollTo(0,1080)")
browser.execute_script("window.scrollTo(0,2160)")
from selenium import webdriverfrom selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(1)
# 검색창 찾기 : 마우스 검색어 넣기
element = browser.find_element(By.CLASS_NAME, "_searchInput_search_input_QXUFf")
element.send_keys("마우스")
# element.send_keys(Keys.ENTER) # 엔터가 안됨.
# 버튼 클릭
browser.find_element(By.CLASS_NAME, "_searchInput_button_search_1n1aw").click()
# 스크롤 이동 : window.scrollTo(x,y) 좌표 지점
# 고정 값을 주면 해상도에 따라 달라질 수 있음.
# 스크롤 움직이는지 확인. 특정 위치 고정 값 지정.
browser.execute_script("window.scrollTo(0,1080)")
browser.execute_script("window.scrollTo(0,2160)")
# 브라우저 끝으로 이동, 동적으로 움직이기 때문에 끝이 아님. 반복 필요
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
# 동적 페이지 스크롤링
# 2초에 한번씩 스크롤 이동
interval = 2
# 현재 문서 높이 가져와서 저장
prev_height = browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
while True:
# 스크롤 이동
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
# 페이지 로딩 대기
time.sleep(interval)
# 스크롤이 진행된 후 현재 문서 높이
curr_height = browser.execute_script("return document.body.scrollHeight")
if curr_height == prev_height:
break
prev_height = curr_height
# 다시 위로 이동
browser.execute_script("window.scrollTo(0,0)")
time.sleep(3)
browser.quit()
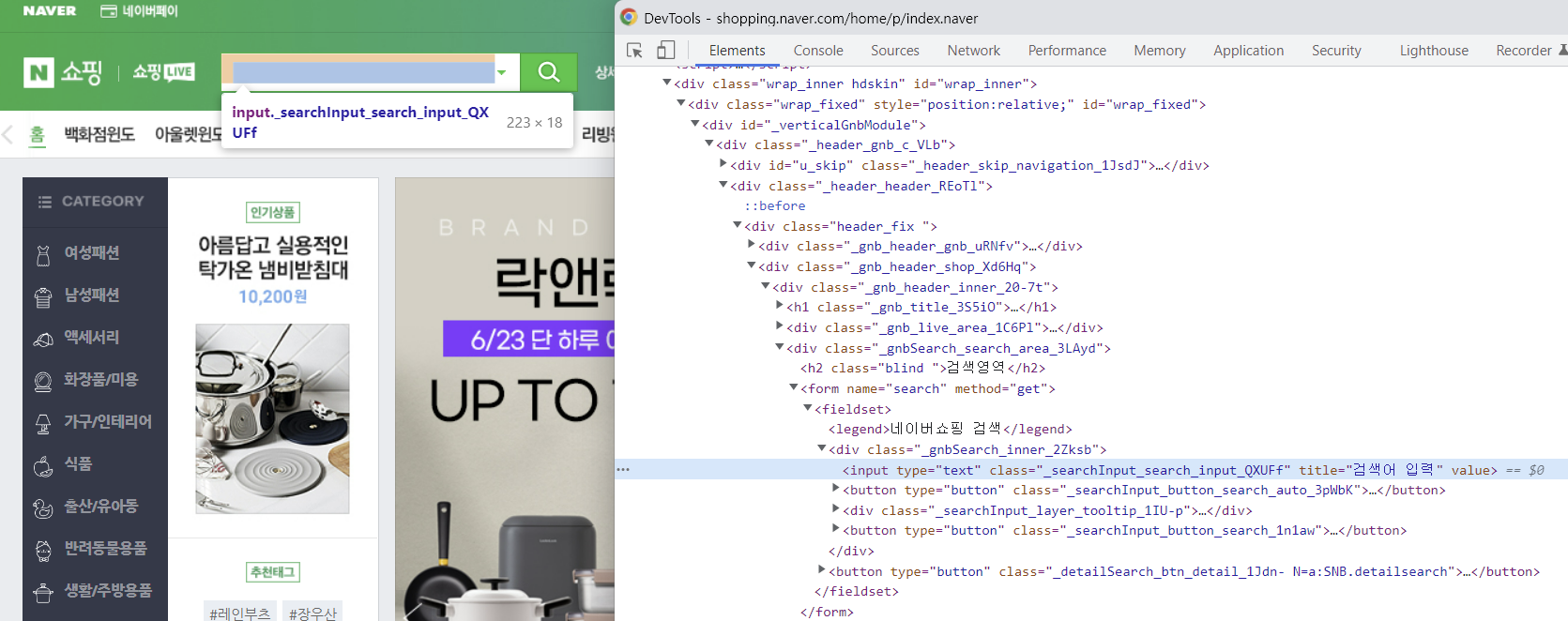
RPAbasic\crawl\selenium1 폴더 - 14_region_scroll.py
내부 스크롤 이동하기 - 특정 요소
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(1)
# 내부 스크롤 이동
element = browser.find_element(By.XPATH, '//*[@id="leftmenuinnerinner"]/div/a[56]')
actions = ActionChains(browser)
# 특정 요소 이동
actions.move_to_element(element).perform()
time.sleep(3)
browser.quit()
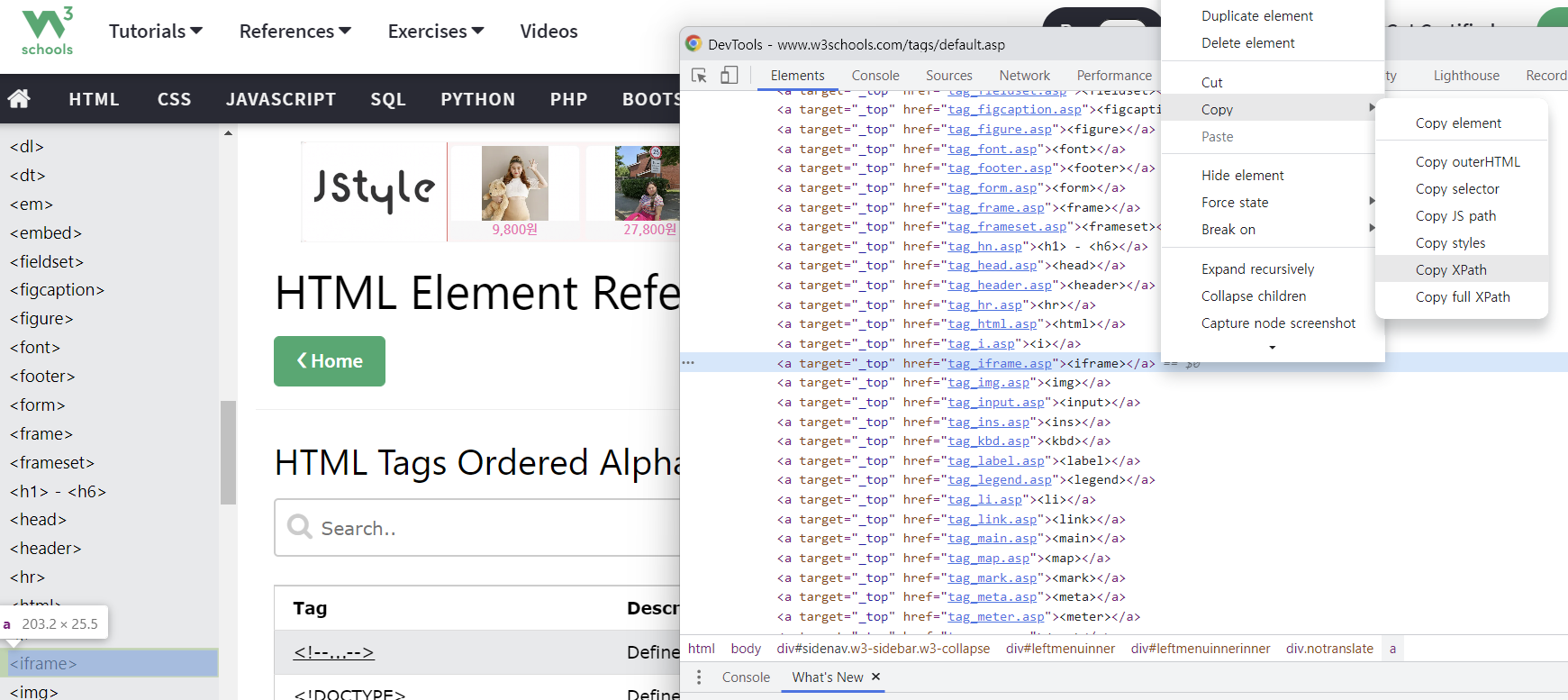
'Python' 카테고리의 다른 글
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(5) (1) | 2022.10.07 |
|---|---|
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(4) (0) | 2022.10.06 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(2) (0) | 2022.10.04 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(1) (0) | 2022.10.03 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(정규표현식)(2) (0) | 2022.10.02 |
'Python' Related Articles
more




Comments