
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 판다스데이터분석
- python수업
- 파이썬크롤링
- 파이썬데이터분석주피터노트북
- 파이썬수업
- SQL
- 주피터노트북맷플롯립
- sql연습
- 맷플롯립
- 파이썬시각화
- 팀플기록
- 주피터노트북데이터분석
- SQL수업
- 주피터노트북
- matplotlib
- 주피터노트북그래프
- 데이터분석시각화
- 판다스그래프
- SQLSCOTT
- 파이썬데이터분석
- Python
- 수업기록
- 파이썬차트
- sql연습하기
- sql따라하기
- 주피터노트북판다스
- python알고리즘
- python데이터분석
- 파이썬알고리즘
- 파이썬
Archives
- Today
- Total
IT_developers
Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(4) 본문
RPA(Robotic Process Automation)
- 웹, 윈도우, 어플리케이션(엑셀 등)을 사전에 설정한 시나리오에 따라 자동적으로 작동하여 수작업을 최소화하는 일련의 프로세스
- RPA 사용 소프트웨어
- Uipath, BluePrism, Automation Anywhere, WinAutomation
- RPA 라이브러리
- pyautogui, pyperclip, selenium
크롤링 : 웹 사이트, 하이퍼링크, 데이터 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것
Selenium
- 브라우저 자동화 개념 적용
- webdriver 이용해서 브라우저 조작, 자동으로 일을 시킬 수 있음
- 웹을 테스트하기 위한 프레임워크
- 자바, 파이썬, C#, 자바 스크립트 등 언어들에서 사용 가능
- 소스 가져오기 + 파싱도 가능
- 브라우저도 접근하기 때문에 차단 될 확률도 적어짐
- 요소
- find_element() : 하나의 요소를 찾을 때
- find_elements() : 여러개의 요소를 찾을 때
- 아이디 값 : find_element(By.ID, "ID 값")
- CSS 선택자 : find_element(By.CSS_SELECTOR, "#선택자 값")
- 클래스 : find_element(By.CLASS_NAME, "NAME 값")
- Xpath : find_element(By.XPATH, '//*[@Xpath 값"]')
- By.NAME, By.CLASS_NAME, By.CSS_SELECTOR, By.ID, By.LINK_TEXT, By.PARTIAL_LINK_TEXT, By.TAG_NAME, By.XPATH
- ActionChain() : 여러 개의 액션을 수행할 경우 차례대로 저장한 후 수행
- 마우스 이동, 마우스 버튼 클릭, key press 등등
- WebDriverWait()
- WebDriverWait(페이지,초) : 주어진 초 동안 페이지를 기다림
- WebDriverWait().until(EC.presence_of_element_located((By.~~, "요소 값")) : 원하는 요소가 나올때까지
- webdriver.ChromeOptions()
- headless = True : 브라우저 창을 띄우지 않고 작업 가능함
RPAbasic\crawl\selenium1 폴더 - 15_download.py
구글 이미지 다운로드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from urllib.request import urlretrieve # 다운로드 전용(페이지, 이미지)
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(1)
# 검색창 찾기 - python입력
element = browser.find_element(By.NAME, "q")
element.send_keys("python")
element.send_keys(Keys.ENTER)
# 동적 페이지 스크롤링
# 2초에 한번씩 스크롤 이동
interval = 2
# 현재 문서 높이 가져와서 저장
prev_height = browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
while True:
# 스크롤 이동
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
# 페이지 로딩 대기
time.sleep(interval)
# 스크롤이 진행된 후 현재 문서 높이
curr_height = browser.execute_script("return document.body.scrollHeight")
if curr_height == prev_height:
# 이미지 더보기 버튼 기능 추가
try:
# 결과 더보기 버튼 찾은 후 클릭
browser.find_element(By.CLASS_NAME, "mye4qd").click()
except:
break
prev_height = curr_height
# 화면에 나온 작은 이미지들
images = browser.find_elements(By.CSS_SELECTOR, "div.bRMDJf.islir > img")
count = 1
for image in images:
try: # 이미지 저장
image.click()
time.sleep(2)
# 큰 이미지 요소 찾기
imgUrl = browser.find_element(
By.XPATH,
'//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[3]/div/a/img',
).get_attribute("src")
# 파일 다운로드 경로
urlretrieve(imgUrl, "./RPAbasic/crawl/image/" + str(count) + ".jpg")
count += 1
except Exception as e:
print("이미지 저장 실패")
# 다시 위로 이동
browser.execute_script("window.scrollTo(0,0)")
# 멈추고 싶다면 TERMINAL 창에서 ctrl + c
time.sleep(3)
browser.quit()
RPAbasic\crawl\selenium1 폴더 - 16_wait1.py
뉴스 기사 댓글
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(1)
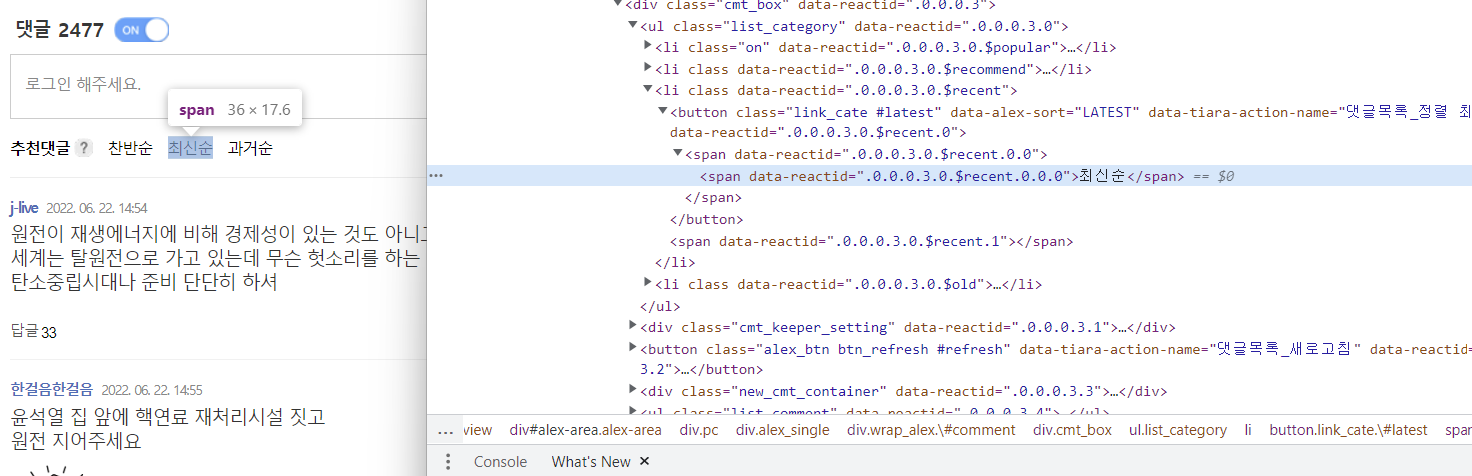
# 댓글을 확인 할 수 있도록 댓글 On 클릭
browser.find_element(By.CLASS_NAME, "btn_foldup").click()
time.sleep(1)
try:
# 최신순 클릭 : 해당 태그가 있는지 검사(5초동안 ==> 요소를 못찾으면 TimeoutException 발생)
WebDriverWait(browser, 5).until(
EC.presence_of_element_located(
(By.XPATH, '//*[@id="alex-area"]/div/div/div/div[3]/ul[1]/li[3]/button')
)
).click()
except TimeoutException:
# 댓글이 없으면 최신순 버튼이 없음.
print("요소 못 찾음")
loop, count = True, 0
# 더보기 10번 클릭
while loop and count < 10:
try:
# browser를 XPATH 요소를 찾는데 5초동안 기다림. 5초가 되기 전에 찾으면 실행됨.
WebDriverWait(browser, 5).until(
EC.presence_of_element_located(
(By.XPATH, '//*[@id="alex-area"]/div/div/div/div[3]/div[3]/button')
)
).click()
count += 1
time.sleep(2)
except:
print("요소 못 찾음")
loop = False
# 댓글 영역을 가져온 후 화면 출력
# 댓글 내용 출력
comment_list = browser.find_elements(By.CSS_SELECTOR, "ul.list_comment > li")
for idx, comment in enumerate(comment_list, 1):
content = comment.find_element(By.CSS_SELECTOR, "div p")
print("[{}] : {}".format(idx, content.text))
time.sleep(3)
browser.quit()
RPAbasic\crawl\selenium1 폴더 - 17_naver.py
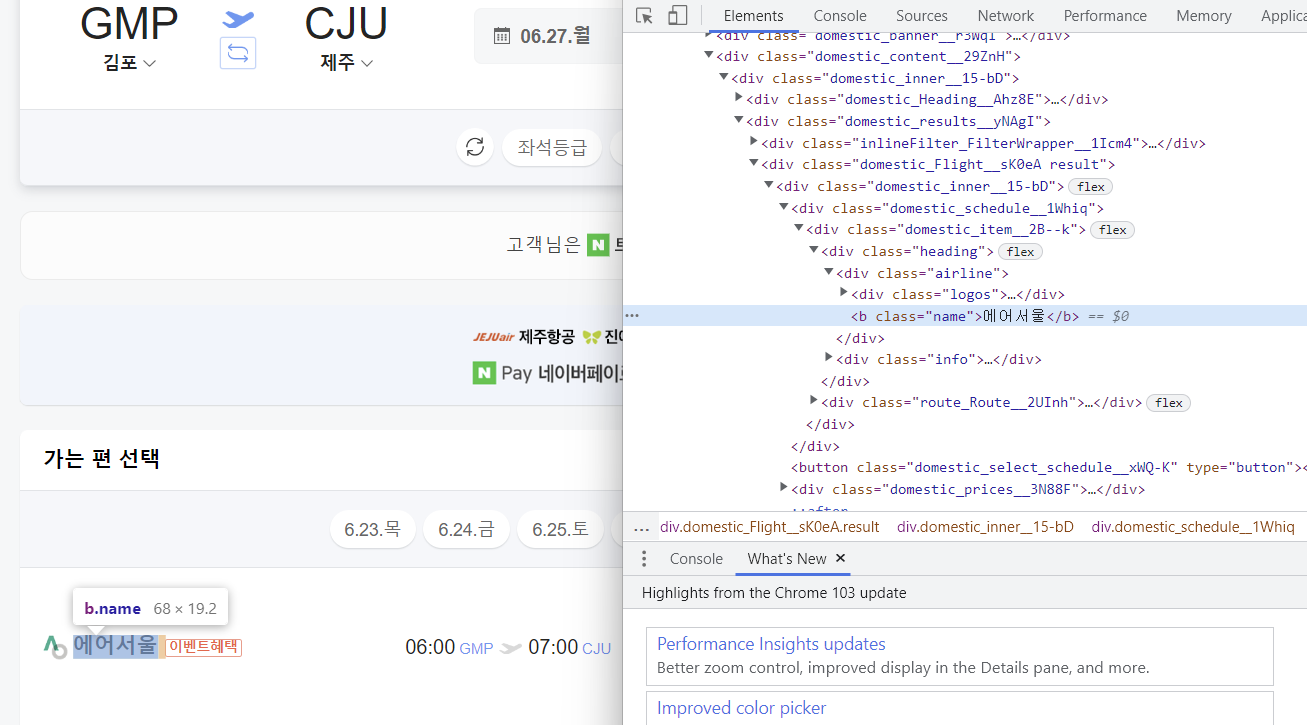
네이버 여행에서 항공권 확인
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(1)
try:
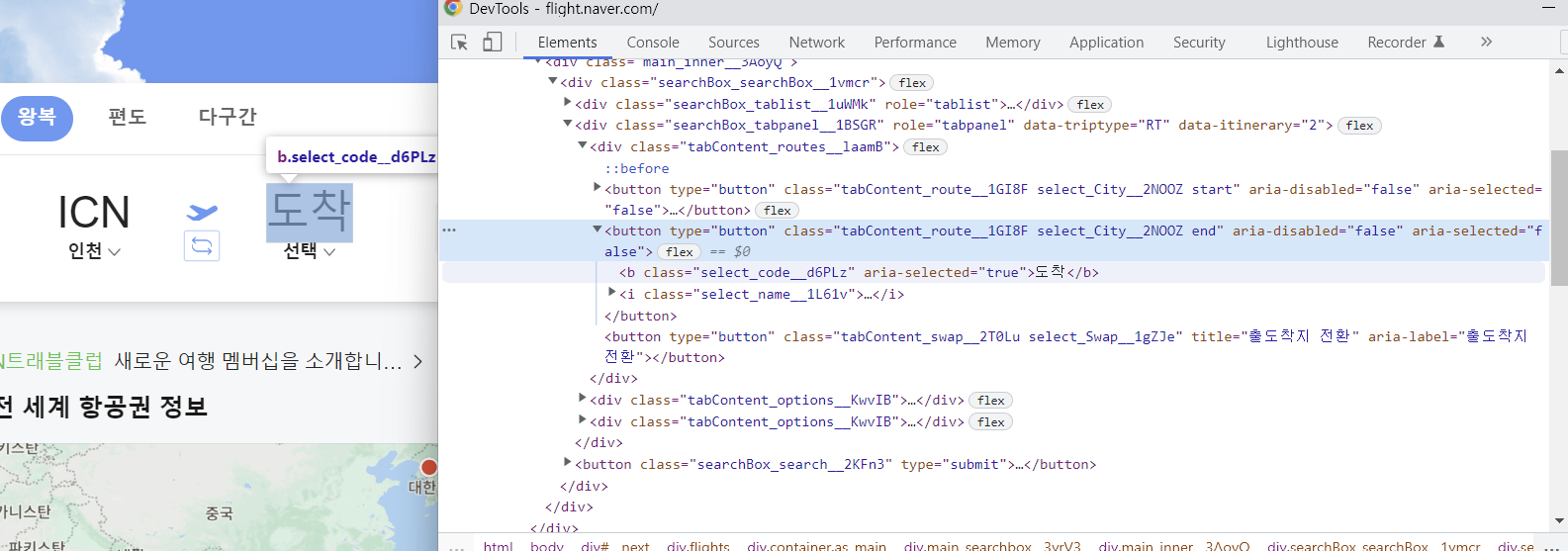
# 도착 클릭
WebDriverWait(browser, 1).until(
EC.presence_of_element_located(
(
By.XPATH,
'//*[@id="__next"]/div/div[1]/div[4]/div/div/div[2]/div[1]/button[2]',
)
)
).click()
time.sleep(1)
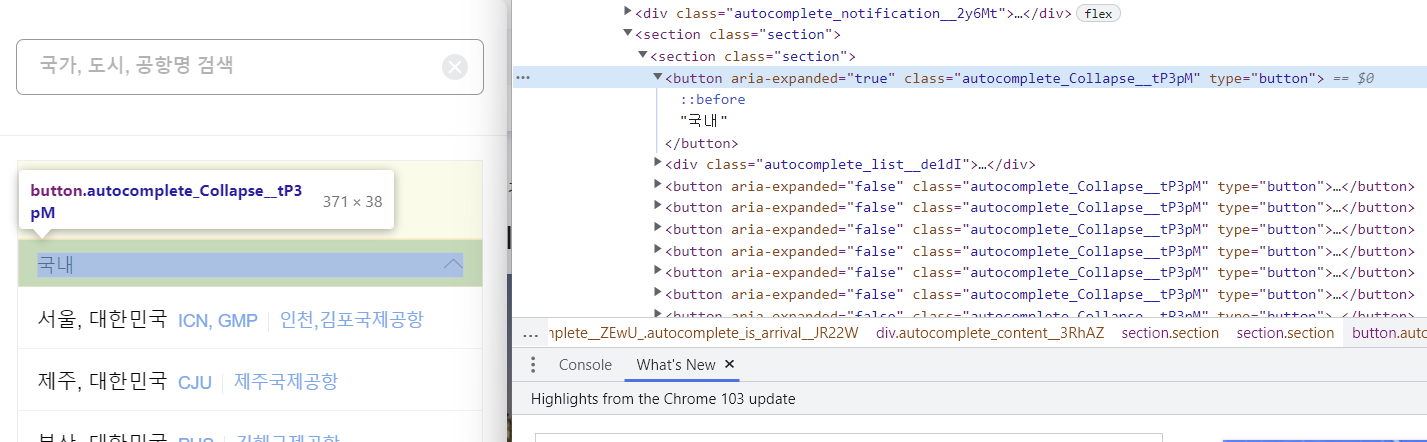
# 국내 클릭
browser.find_element(
By.XPATH, '//*[@id="__next"]/div/div[1]/div[9]/div[2]/section/section/button[1]'
).click()
time.sleep(2)
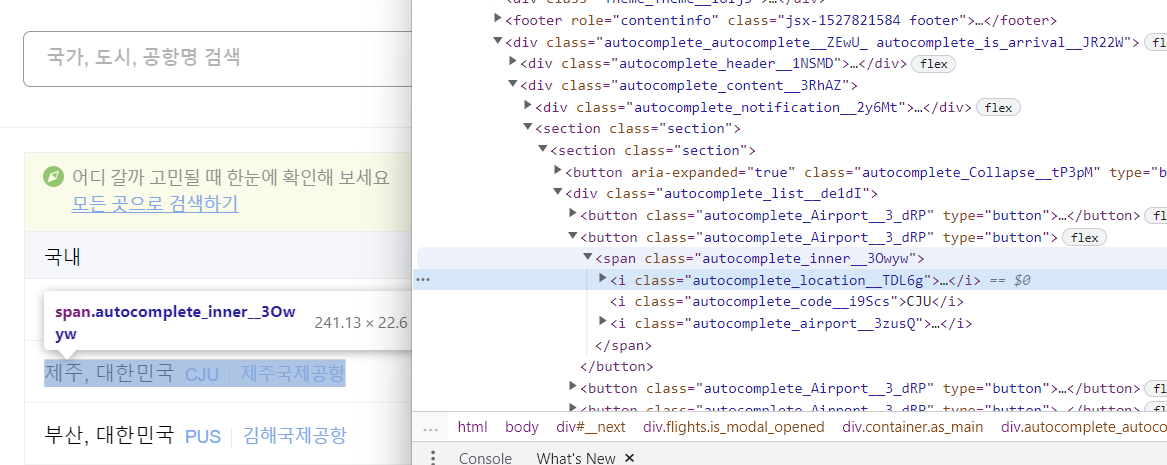
# 제주 클릭
browser.find_element(
By.XPATH,
'//*[@id="__next"]/div/div[1]/div[9]/div[2]/section/section/div/button[2]/span',
).click()
# 가는날 클릭
browser.find_element(
By.XPATH, '//*[@id="__next"]/div/div[1]/div[4]/div/div/div[2]/div[2]/button[1]'
).click()
time.sleep(2)
# 가는날짜 클릭 == 6월 27일
browser.find_element(
By.CSS_SELECTOR,
"div.awesome-calendar > div:nth-child(2) tr:nth-child(5) > td:nth-child(2) > button",
).click()
time.sleep(2)
# 오는날짜 클릭 == 6월 30일
browser.find_element(
By.XPATH,
'//*[@id="__next"]/div/div[1]/div[9]/div[2]/div[1]/div[2]/div/div[2]/table/tbody/tr[5]/td[5]/button',
).click()
# 항공권 검색 클릭
browser.find_element(
By.CSS_SELECTOR, "div.main_searchbox__3vrV3 > div > div > button"
).click()
# 항공권 검색 결과 출력(항공사)
airline = WebDriverWait(browser, 10).until(
EC.presence_of_element_located(
(
By.CSS_SELECTOR,
"div.domestic_schedule__1Whiq > div > div.heading > div.airline",
)
)
)
print(airline.text)
except Exception as e:
print(e)
time.sleep(3)
browser.quit()



RPAbasic\crawl\selenium1 폴더 -18_youtube2.py
Youtube 검색어 넣고 검색 결과 출력
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
options = webdriver.ChromeOptions()
# 브라우저 창을 띄우지 않음
options.headless = True
browser = webdriver.Chrome(options=options)
browser.maximize_window()
time.sleep(2)
# 검색어 넣기
# element = browser.find_element(By.ID, "search")
element = browser.find_element(By.NAME, "search_query")
element.send_keys("아이유")
element.send_keys(Keys.ENTER)
time.sleep(2)
# 검색 결과 출력
titles = browser.find_elements(By.TAG_NAME, "h3")
for title in titles:
print(title.text)
time.sleep(3)
browser.quit()

다 실행되는 건 아니고 꼭 버튼을 클릭해야 활성화 되는 것들은 오류 발생 : ElementClickInterceptedException
모든게 해드리스가 되는건 아님.
단순작업 페이지에서 소스 가지고오기 정도 가능
options = webdriver.ChromeOptions()
options.headless = True
browser = webdriver.Chrome(options=options)

'Python' 카테고리의 다른 글
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(6) (1) | 2022.10.08 |
|---|---|
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(5) (1) | 2022.10.07 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(3) (1) | 2022.10.05 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(2) (0) | 2022.10.04 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(1) (0) | 2022.10.03 |
'Python' Related Articles
more




Comments