
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- python알고리즘
- python수업
- sql따라하기
- sql연습하기
- 파이썬알고리즘
- 주피터노트북판다스
- 파이썬시각화
- sql연습
- 데이터분석시각화
- 파이썬차트
- 주피터노트북
- python데이터분석
- 파이썬크롤링
- 맷플롯립
- 팀플기록
- 수업기록
- matplotlib
- Python
- 주피터노트북그래프
- 주피터노트북데이터분석
- 파이썬데이터분석
- 판다스그래프
- 주피터노트북맷플롯립
- SQLSCOTT
- 판다스데이터분석
- 파이썬수업
- 파이썬
- SQL수업
- 파이썬데이터분석주피터노트북
- SQL
Archives
- Today
- Total
IT_developers
Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(6) 본문
RPA(Robotic Process Automation)
- 웹, 윈도우, 어플리케이션(엑셀 등)을 사전에 설정한 시나리오에 따라 자동적으로 작동하여 수작업을 최소화하는 일련의 프로세스
- RPA 사용 소프트웨어
- Uipath, BluePrism, Automation Anywhere, WinAutomation
- RPA 라이브러리
- pyautogui, pyperclip, selenium
크롤링 : 웹 사이트, 하이퍼링크, 데이터 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것
Selenium
- 브라우저 자동화 개념 적용
- webdriver 이용해서 브라우저 조작, 자동으로 일을 시킬 수 있음
- 웹을 테스트하기 위한 프레임워크
- 자바, 파이썬, C#, 자바 스크립트 등 언어들에서 사용 가능
- 소스 가져오기 + 파싱도 가능
- 브라우저도 접근하기 때문에 차단 될 확률도 적어짐
- 요소
- find_element() : 하나의 요소를 찾을 때
- find_elements() : 여러개의 요소를 찾을 때
- 아이디 값 : find_element(By.ID, "ID 값")
- CSS 선택자 : find_element(By.CSS_SELECTOR, "#선택자 값")
- 클래스 : find_element(By.CLASS_NAME, "NAME 값")
- Xpath : find_element(By.XPATH, '//*[@Xpath 값"]')
- By.NAME, By.CLASS_NAME, By.CSS_SELECTOR, By.ID, By.LINK_TEXT, By.PARTIAL_LINK_TEXT, By.TAG_NAME, By.XPATH
- ActionChain() : 여러 개의 액션을 수행할 경우 차례대로 저장한 후 수행
- 마우스 이동, 마우스 버튼 클릭, key press 등등
- WebDriverWait()
- WebDriverWait(페이지,초) : 주어진 초 동안 페이지를 기다림
- WebDriverWait().until(EC.presence_of_element_located((By.~~, "요소 값")) : 원하는 요소가 나올때까지
- webdriver.ChromeOptions()
- headless = True : 브라우저 창을 띄우지 않고 작업 가능함
RPAbasic\crawl\selenium1 폴더 - 21_registration1.py
사업자등록상태 조회 자동화


주소를 직접 들어가면 로그인이 필요하기 때문에 다른 주소로 조회

from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
browser = webdriver.Chrome()
browser.get(
)
browser.maximize_window()
# 사업자등록번호 입력
# 767-82-00017
browser.find_element(By.ID, "bsno").send_keys("767-82-00017")
time.sleep(1)
# 조회하기 클릭
browser.find_element(By.ID, "trigger5").click()
time.sleep(2)
# 사업자등록상태 조회
# 상태 화면 출력
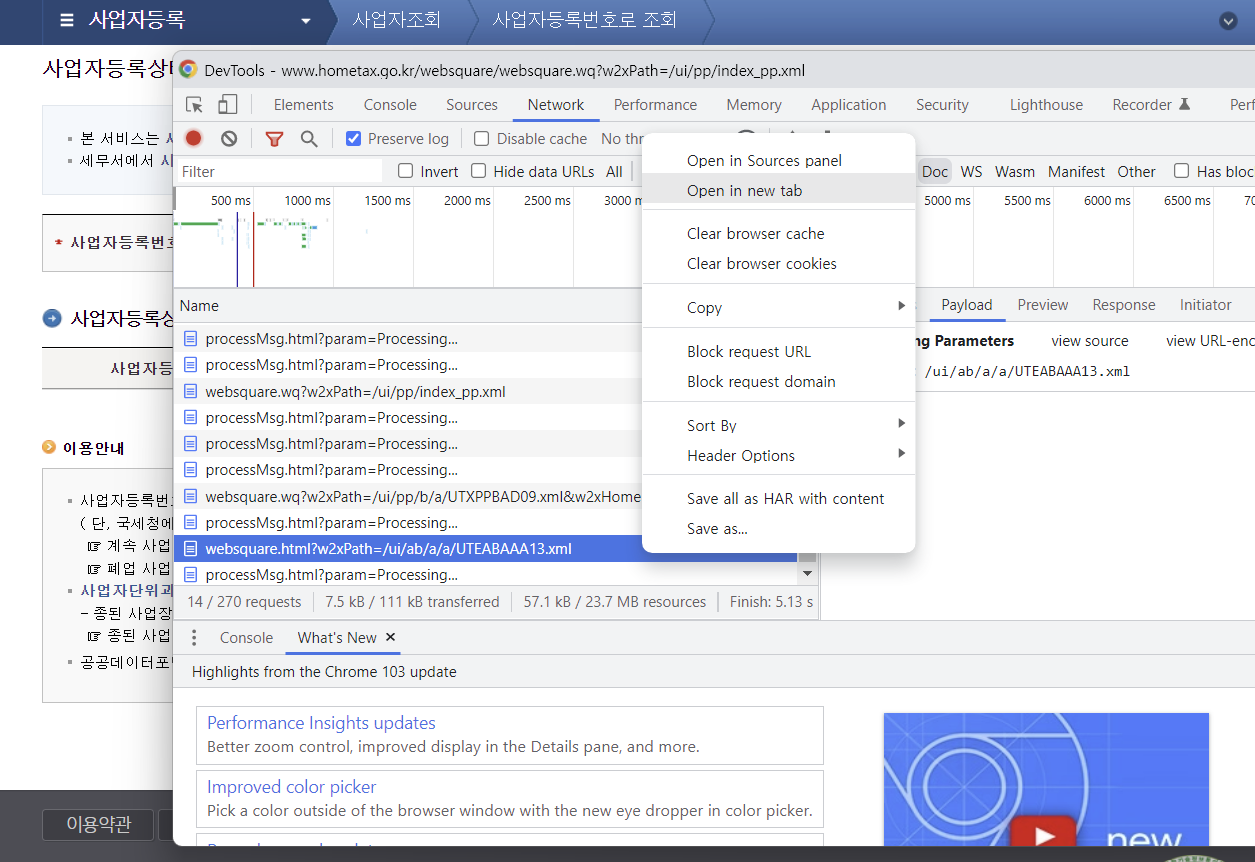
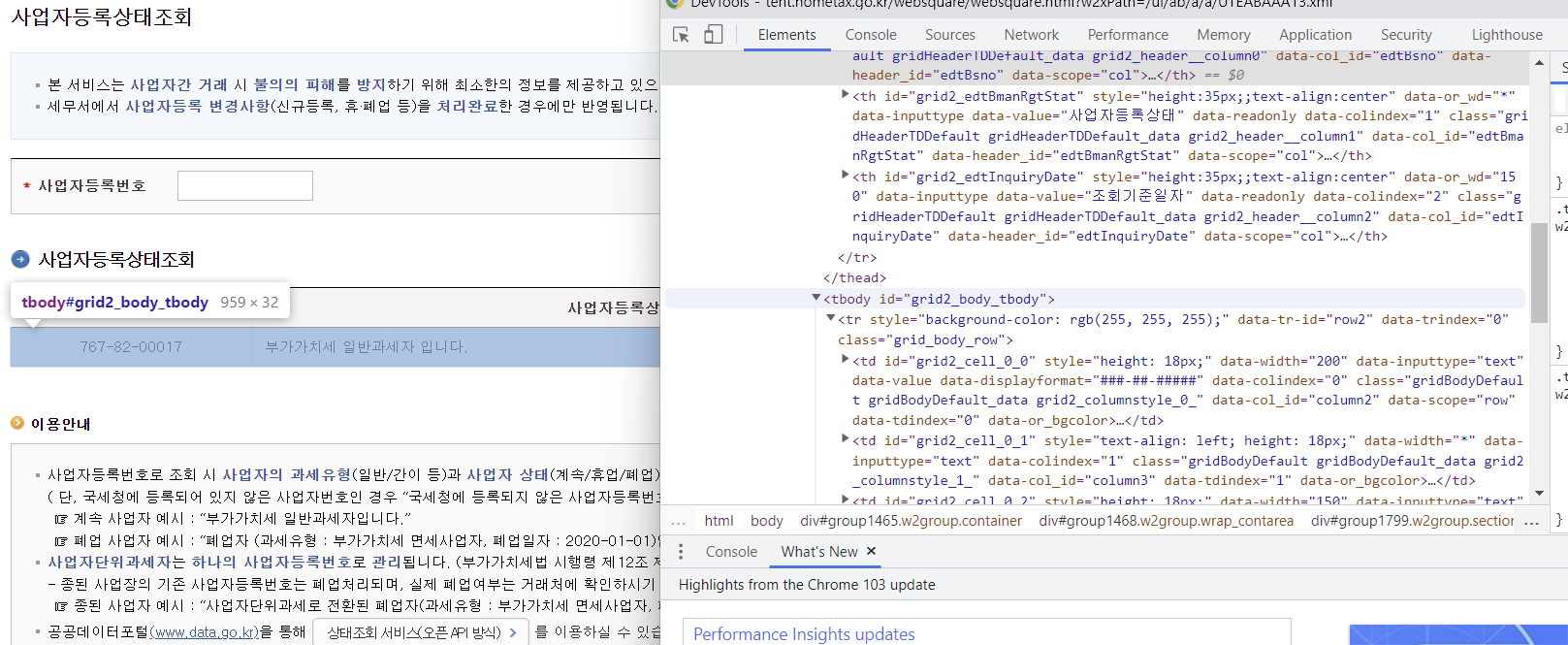
tbody = browser.find_element(By.XPATH, '//*[@id="grid2_body_tbody"]')
print(tbody.text) #767-82-00017 부가가치세 일반과세자 입니다. 2022-06-23
# bs4 사용
soup = BeautifulSoup(browser.page_source, "lxml")
tds = soup.select("#grid2_body_tbody > tr > td")
for td in tds:
print(td.get_text())
time.sleep(3)
browser.quit()


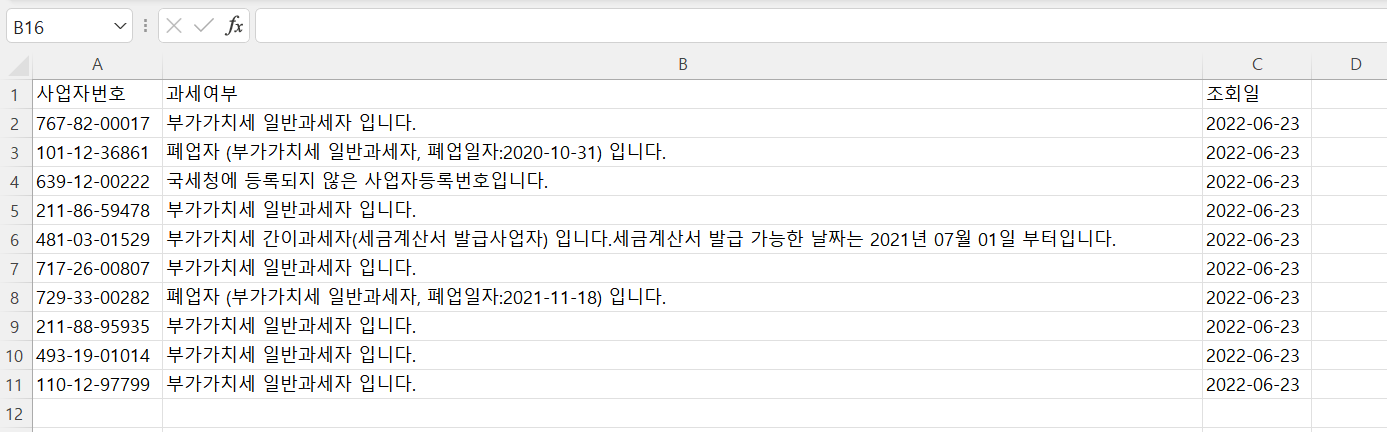
RPAbasic\crawl\selenium1 폴더 - 21_registration2.py
사업자등록상태 조회(10개) 자동화 + 엑셀 작업
전제내용 조회 후 해당 내용 엑셀에 저장
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
from openpyxl import load_workbook
browser = webdriver.Chrome()
browser.get(
)
browser.maximize_window()
# 엑셀 작업
wb = load_workbook("./RPAbasic/crawl/download/business_number.xlsx")
ws = wb.active
# 엑셀 전체 내용 출력(행,열 == x,y)
# 잘 읽어오는지 확인
for x in range(2, ws.max_row + 1):
for y in range(1, ws.max_column + 1):
print(ws.cell(x, y).value, end=" ")
print()
# 엑셀 부분 출력
for x in range(2, ws.max_row + 1):
# 사업자 등록번호 읽어 오기
bsn = ws.cell(x, 1).value
print("===사업자등록번호===", bsn)
browser.find_element(By.ID, "bsno").send_keys(bsn)
# 조회하기 클릭
browser.find_element(By.ID, "trigger5").click()
time.sleep(2)
# bs4 사용
soup = BeautifulSoup(browser.page_source, "lxml")
tds = soup.select("#grid2_body_tbody > tr > td")
# 하나의 리스트로 생성
list1 = []
# 조회된 정보를 하나의 리스트 구조로 만들기
for td in tds:
list1.append(td.get_text())
# 엑셀 저장
ws.append(list1)
time.sleep(5)
del soup
# for문 종료 후 기존 내용 삭제
# 2번 행부터 10개 삭제
ws.delete_rows(2,10)
# 저장
wb.save("./RPAbasic/crawl/download/business_number.xlsx")
time.sleep(3)
browser.quit()


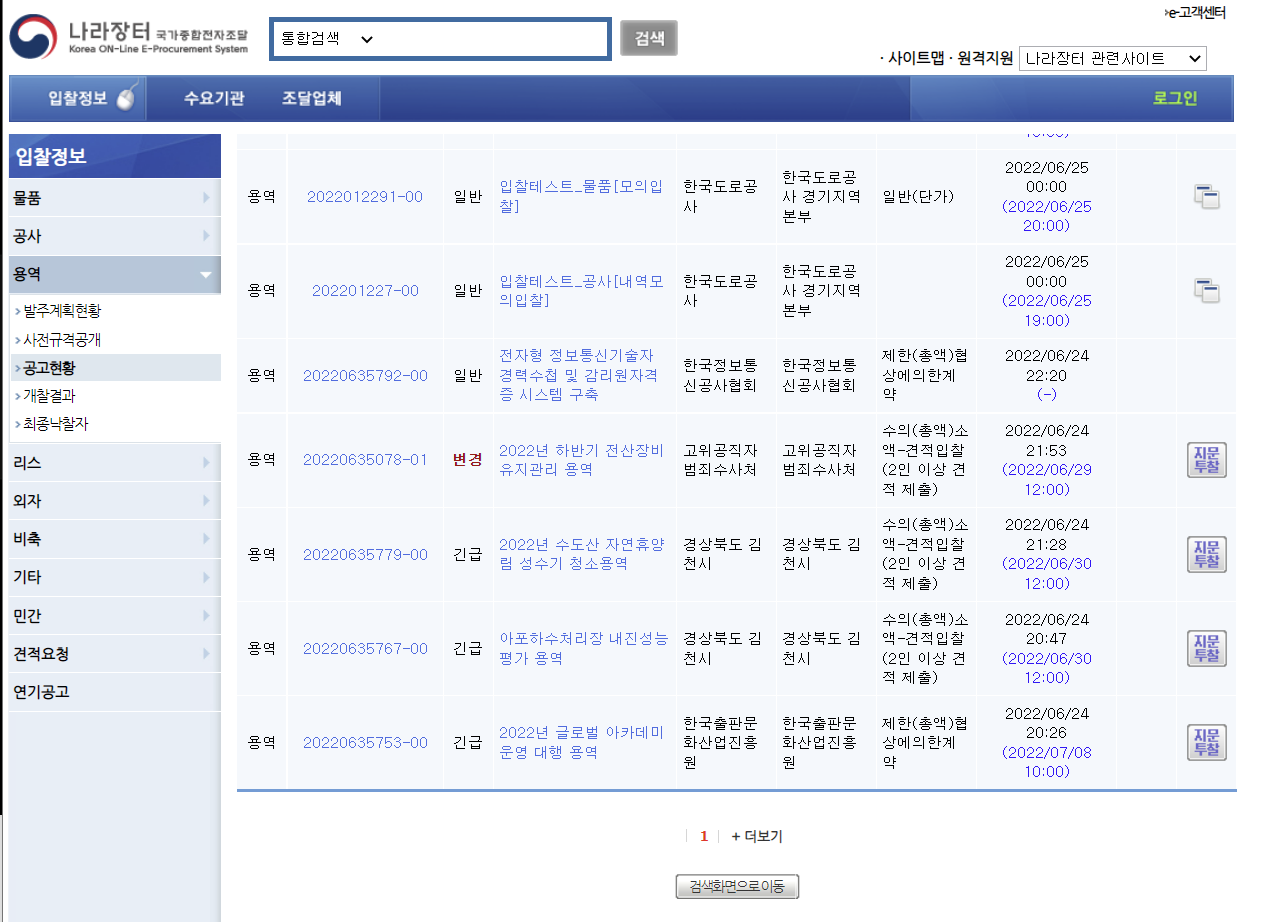
RPAbasic\crawl\selenium1 폴더 - 22_nara.py
나라장터 용역 공고 자동화 + 엑셀
주소가 잘 안잡혀서 더보기 클릭 후 주소 가지고 오기
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from openpyxl import Workbook
# 엑셀
wb = Workbook()
# 기본 시트 활성화
ws = wb.active
# 시트명 새로 지정
ws.title = "나라장터 용역공고"
# 타이틀 행 추가
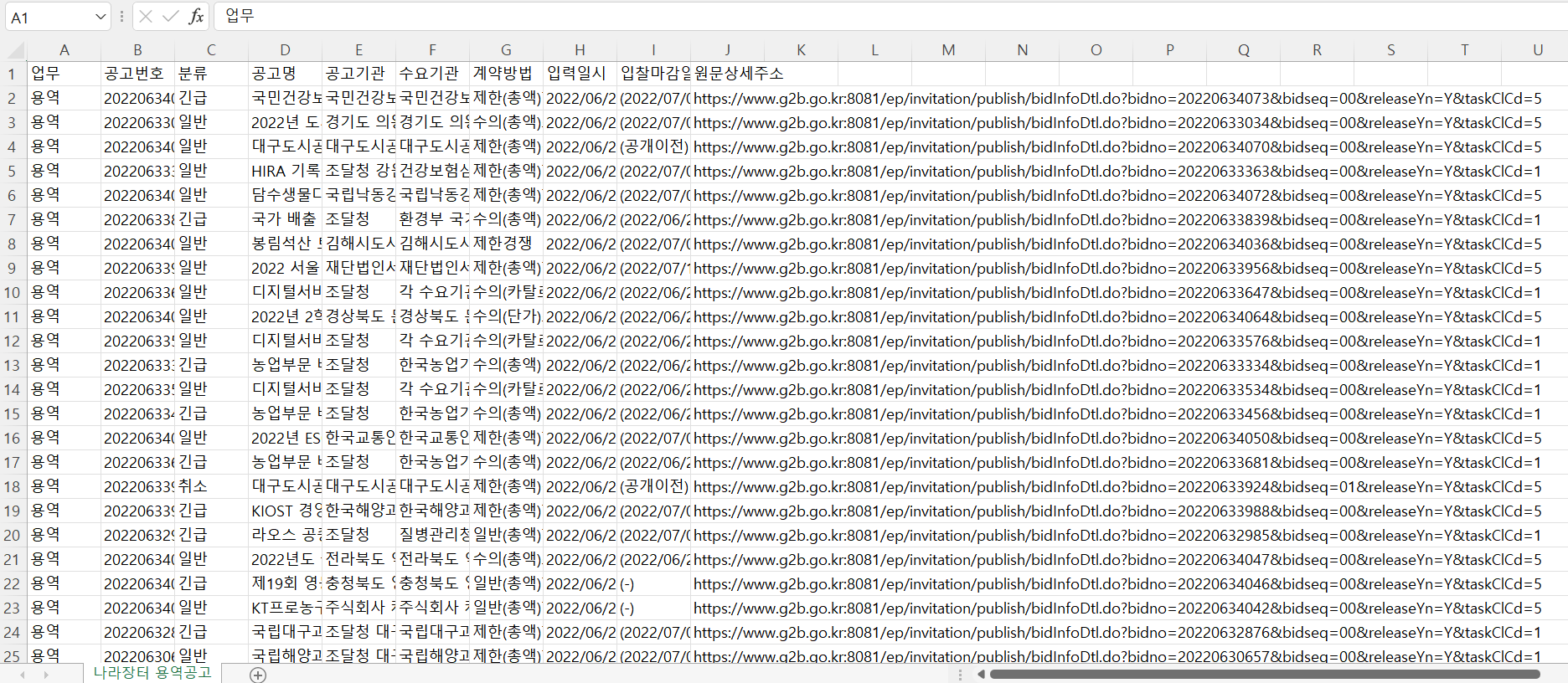
ws.append(
["업무", "공고번호", "분류", "공고명", "공고기관", "수요기관", "계약방법", "입력일시", "입찰마감일시", "원문상세주소"]
)
# url 구별
# taskClCds=5 용역에 대한 정보만 불러오기
# fromBidDt : 시작 날짜, toBidDt : 끝날짜, currentPageNo : 페이지 나누기
browser = webdriver.Chrome()
# url 3번 조회
for i in range(1, 4):
url += "bidSearchType=1&budgetCompare=&detailPrdnm=&detailPrdnmNo=&downBudget=&"
url += "fromBidDt=2022%2F05%2F24&fromOpenBidDt=&industry=&industryCd=&instNm=&"
url += "instSearchRangeType=&intbidYn=&orgArea=&procmntReqNo=&radOrgan=1&"
url += "recordCountPerPage=30&refNo=®Yn=Y&searchDtType=1&searchType=1&"
url += "strArea=&taskClCds=5&toBidDt=2022%2F06%2F23&toOpenBidDt=&upBudget=&"
url += "currentPageNo=" + str(i) + "&maxPageViewNoByWshan=2&"
browser.get(url)
browser.maximize_window()
# 업무,공고번호, 분류,공고명,공고기관,수요기관,계약방법,입력일시(입찰마감일시)
tbody = browser.find_element(By.XPATH, '//*[@id="resultForm"]/div[2]/table/tbody')
trs = tbody.find_elements(By.TAG_NAME, "tr")
# td, tr로 구분이 어렵고 전체를 불러와서 순서를 정해서 가지고 오기
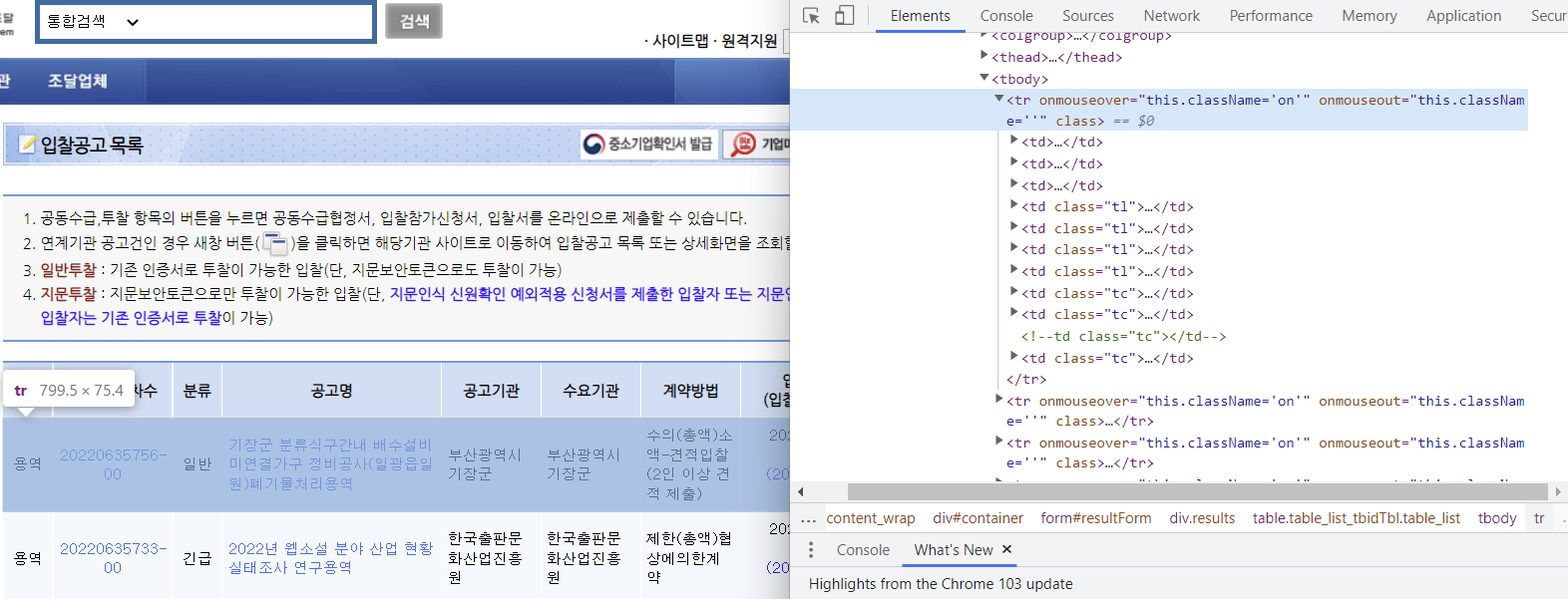
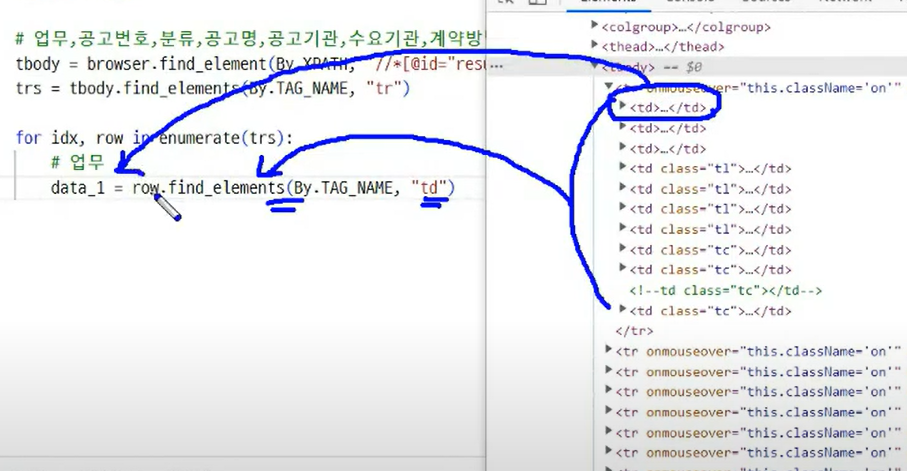
입력일시와 마감일시 <br>확인
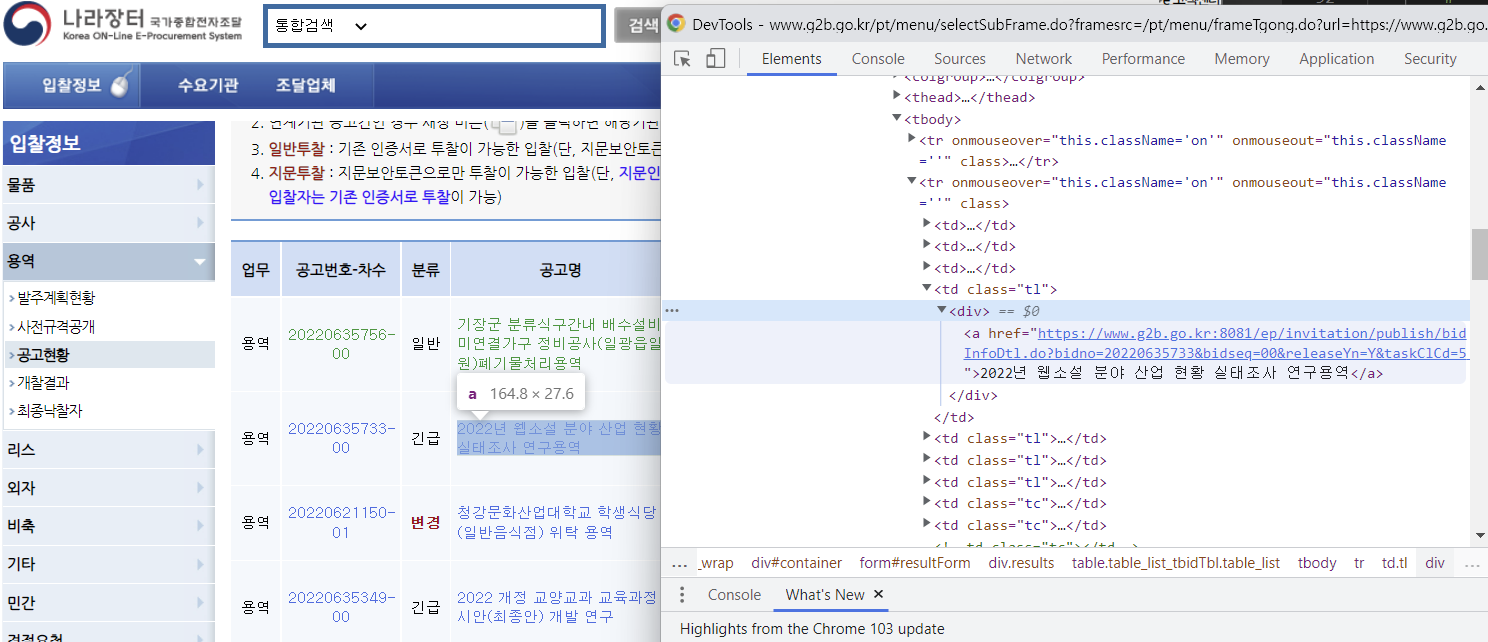
공고명에 연결되어 있는 href 찾기
for idx, row in enumerate(trs):
# 업무
data_1 = row.find_elements(By.TAG_NAME, "td")[0]
# 공고번호
data_2 = row.find_elements(By.TAG_NAME, "td")[1]
# 분류
data_3 = row.find_elements(By.TAG_NAME, "td")[2]
# 공고명
data_4 = row.find_elements(By.TAG_NAME, "td")[3]
# 공고기관
data_5 = row.find_elements(By.TAG_NAME, "td")[4]
# 수요기관
data_6 = row.find_elements(By.TAG_NAME, "td")[5]
# 계약방법
data_7 = row.find_elements(By.TAG_NAME, "td")[6]
# 입력일시(+마감일시)
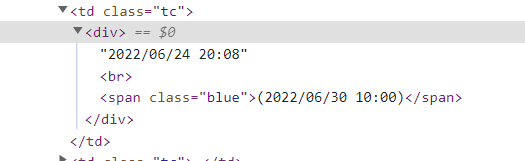
data_8 = row.find_elements(By.TAG_NAME, "td")[7]
# 입력일시와 마감일시를 따로 작업.
# <br>기준으로 나눠서 뽑음
reg_date = data_8.text.split("\n")[0]
end_date = data_8.text.split("\n")[1]
# 입찰공고 상세 주소
data_link = row.find_element(By.TAG_NAME, "a").get_attribute("href")
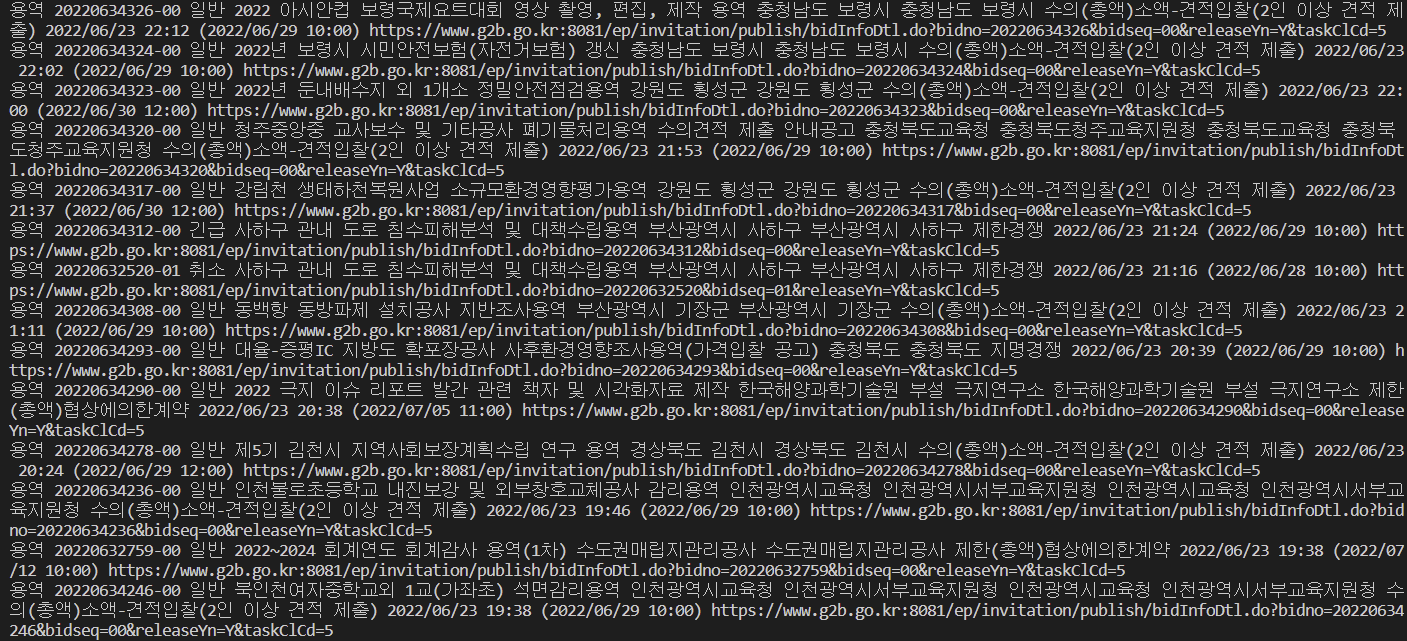
print(
data_1.text,
data_2.text,
data_3.text,
data_4.text,
data_5.text,
data_6.text,
data_7.text,
reg_date, # 이미 텍스트로 뽑아놓음.
end_date,
data_link,
)
# 엑셀에 저장
ws.append(
[
data_1.text,
data_2.text,
data_3.text,
data_4.text,
data_5.text,
data_6.text,
data_7.text,
reg_date,
end_date,
data_link,
]
)
time.sleep(2)
# 엑셀 저장
wb.save("./RPAbasic/crawl/download/nara.xlsx")
time.sleep(3)
browser.quit()
'Python' 카테고리의 다른 글
| Python 데이터 분석 - 환경 설정(아나콘다, 주피터노트북) (0) | 2022.10.16 |
|---|---|
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(7) (0) | 2022.10.09 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(5) (1) | 2022.10.07 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(4) (0) | 2022.10.06 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(3) (1) | 2022.10.05 |
'Python' Related Articles
more




Comments