
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 파이썬시각화
- 주피터노트북맷플롯립
- python알고리즘
- SQL
- 파이썬데이터분석주피터노트북
- python데이터분석
- SQLSCOTT
- matplotlib
- 파이썬
- sql연습
- 파이썬차트
- 주피터노트북
- Python
- 파이썬크롤링
- sql연습하기
- 주피터노트북판다스
- 판다스그래프
- 파이썬수업
- SQL수업
- 주피터노트북데이터분석
- 데이터분석시각화
- 수업기록
- 팀플기록
- 맷플롯립
- 판다스데이터분석
- python수업
- 파이썬데이터분석
- sql따라하기
- 주피터노트북그래프
- 파이썬알고리즘
Archives
- Today
- Total
IT_developers
Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(5) 본문
RPA(Robotic Process Automation)
- 웹, 윈도우, 어플리케이션(엑셀 등)을 사전에 설정한 시나리오에 따라 자동적으로 작동하여 수작업을 최소화하는 일련의 프로세스
- RPA 사용 소프트웨어
- Uipath, BluePrism, Automation Anywhere, WinAutomation
- RPA 라이브러리
- pyautogui, pyperclip, selenium
크롤링 : 웹 사이트, 하이퍼링크, 데이터 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것
Selenium
- 브라우저 자동화 개념 적용
- webdriver 이용해서 브라우저 조작, 자동으로 일을 시킬 수 있음
- 웹을 테스트하기 위한 프레임워크
- 자바, 파이썬, C#, 자바 스크립트 등 언어들에서 사용 가능
- 소스 가져오기 + 파싱도 가능
- 브라우저도 접근하기 때문에 차단 될 확률도 적어짐
- 요소
- find_element() : 하나의 요소를 찾을 때
- find_elements() : 여러개의 요소를 찾을 때
- 아이디 값 : find_element(By.ID, "ID 값")
- CSS 선택자 : find_element(By.CSS_SELECTOR, "#선택자 값")
- 클래스 : find_element(By.CLASS_NAME, "NAME 값")
- Xpath : find_element(By.XPATH, '//*[@Xpath 값"]')
- By.NAME, By.CLASS_NAME, By.CSS_SELECTOR, By.ID, By.LINK_TEXT, By.PARTIAL_LINK_TEXT, By.TAG_NAME, By.XPATH
- ActionChain() : 여러 개의 액션을 수행할 경우 차례대로 저장한 후 수행
- 마우스 이동, 마우스 버튼 클릭, key press 등등
- WebDriverWait()
- WebDriverWait(페이지,초) : 주어진 초 동안 페이지를 기다림
- WebDriverWait().until(EC.presence_of_element_located((By.~~, "요소 값")) : 원하는 요소가 나올때까지
- webdriver.ChromeOptions()
- headless = True : 브라우저 창을 띄우지 않고 작업 가능함
RPAbasic\crawl\selenium1 폴더 - 19_danawa2.py
다나와 상품 자동화 - 애플 노트북 검색 결과 출력
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from bs4 import BeautifulSoup
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(1)
# 제조사 더보기 클릭
WebDriverWait(browser, 3).until(
EC.presence_of_element_located(
(By.XPATH, '//*[@id="dlMaker_simple"]/dd/div[2]/button[1]')
)
).click()
# Apple 버튼 클릭
browser.find_element(
By.XPATH, '//*[@id="selectMaker_simple_priceCompare_A"]/li[17]/label'
).click()
# 제품 목록이 화면에 로딩되도록 대기
time.sleep(5)
# 상품 정보 추출 - 상품명, 가격(첫번째), 이미지 src 출력
# 상품 목록 리스트 가져오기
product_list = browser.find_elements(
# 광고와 제일 마지막에 있는 비어있는 리스트는 제외
By.CSS_SELECTOR,
"div.main_prodlist_list > ul> li:not(.prod_ad_item):not(.product-pot)",
)
# 현재 페이지 / 크롤링할 페이지 수 지정
cur_page, target_crawl_num = 1, 6
# 번호 출력
idx = 1
# 페이지 제어 총 6페이지
while cur_page <= target_crawl_num:
# 셀레니움이 잘 안될 땐 BeautifulSoup
# 매번 받아서 파싱
soup = BeautifulSoup(browser.page_source, "lxml")
product_list = soup.select(
"div.main_prodlist_list > ul> li:not(.prod_ad_item):not(.product-pot)"
)
print(product_list)
# 현재 페이지 출력
print("=============Current Page : {}".format(cur_page))
# 상품 정보 출력 1페이지당 30개
for product in product_list:
# 제품명
# 셀레니움 : product_name = product.find_element(By.CSS_SELECTOR, "p > a").text.strip()
product_name = product.select_one("p > a").text.strip()
# 가격
# 셀레니움 : product_price = product.find_element(
# By.CSS_SELECTOR, "p.price_sect > a"
# ).text.strip()
product_price = product.select_one("p.price_sect > a").text.strip()
# 이미지 경로
# 셀레니움 : product_image = product.find_element(By.CSS_SELECTOR, ".thumb_image img")
product_image = product.select_one(".thumb_image img")
#셀레니움
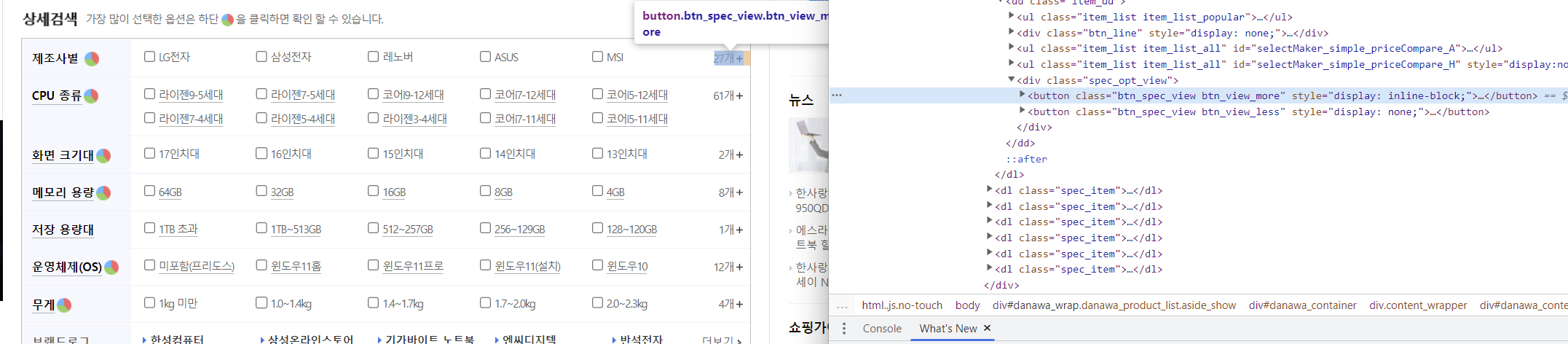
제조사 별 더보기 클릭
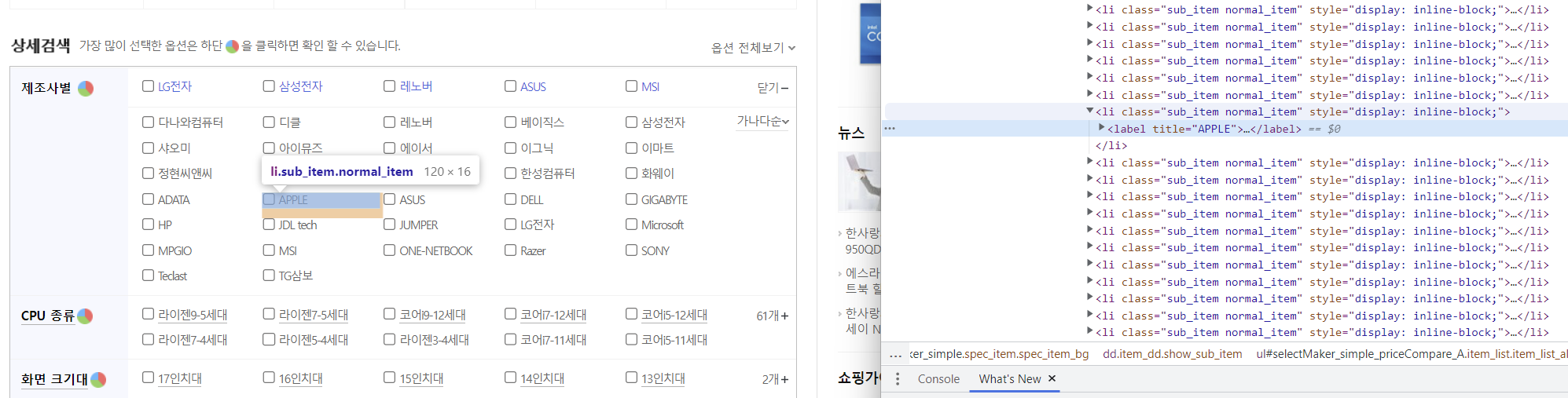
Apple 클릭
# if product_image.get_attribute("data-original"):
# product_image = product_image.get_attribute("data-original")
# else:
# product_image = product_image.get_attribute("src")
if product_image.get("data-original"):
product_image = product_image.get("data-original")
else:
product_image = product_image.get("src")
if "http:" not in product_image:
product_image = "http:" + product_image
print(idx, product_name, product_price, product_image)
idx += 1
# for문 종료
print() # 한페이지 끝남.
browser.save_screenshot(
"./RPAbasic/crawl/download/target_page{}.png".format(cur_page)
)
# 현재 페이지 번호 변경
cur_page += 1
if cur_page > target_crawl_num:
print("크롤링 성공")
break
# 다음페이지 클릭
# 페이지 클릭 시 : #productListArea > div.prod_num_nav > div > div > a:nth-child(2)
# 페이지 변화 필요하기 위해 자리를 잡아두고 페이지 값 넣어주기
WebDriverWait(browser, 2).until(
EC.presence_of_element_located(
(By.CSS_SELECTOR, "div.number_wrap > a:nth-child({})".format(cur_page))
)
).click()
# soup 삭제
del soup
# 다음 페이지 로딩될 때까지 기다리기
time.sleep(3)
# while문 종료
time.sleep(3)
browser.quit()


RPAbasic\crawl\selenium1 폴더 - 19_danawa3_excel.py
다나와 상품화 검색 후 엑셀 저장
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from bs4 import BeautifulSoup
from openpyxl import Workbook
from openpyxl.drawing.image import Image
import requests
from io import BytesIO # 웹상에 있는 이미지를 다운을 위해 필요
# 엑셀 파일 생성
wb = Workbook()
# 기본 시트 활성화
ws = wb.active
# 시트명 새로 지정
ws.title = "애플"
# 제목행 너비 조절
ws.column_dimensions["B"].width = 55
ws.column_dimensions["C"].width = 20
ws.column_dimensions["D"].width = 96
ws.column_dimensions["E"].width = 10
# 타이틀 행 추가
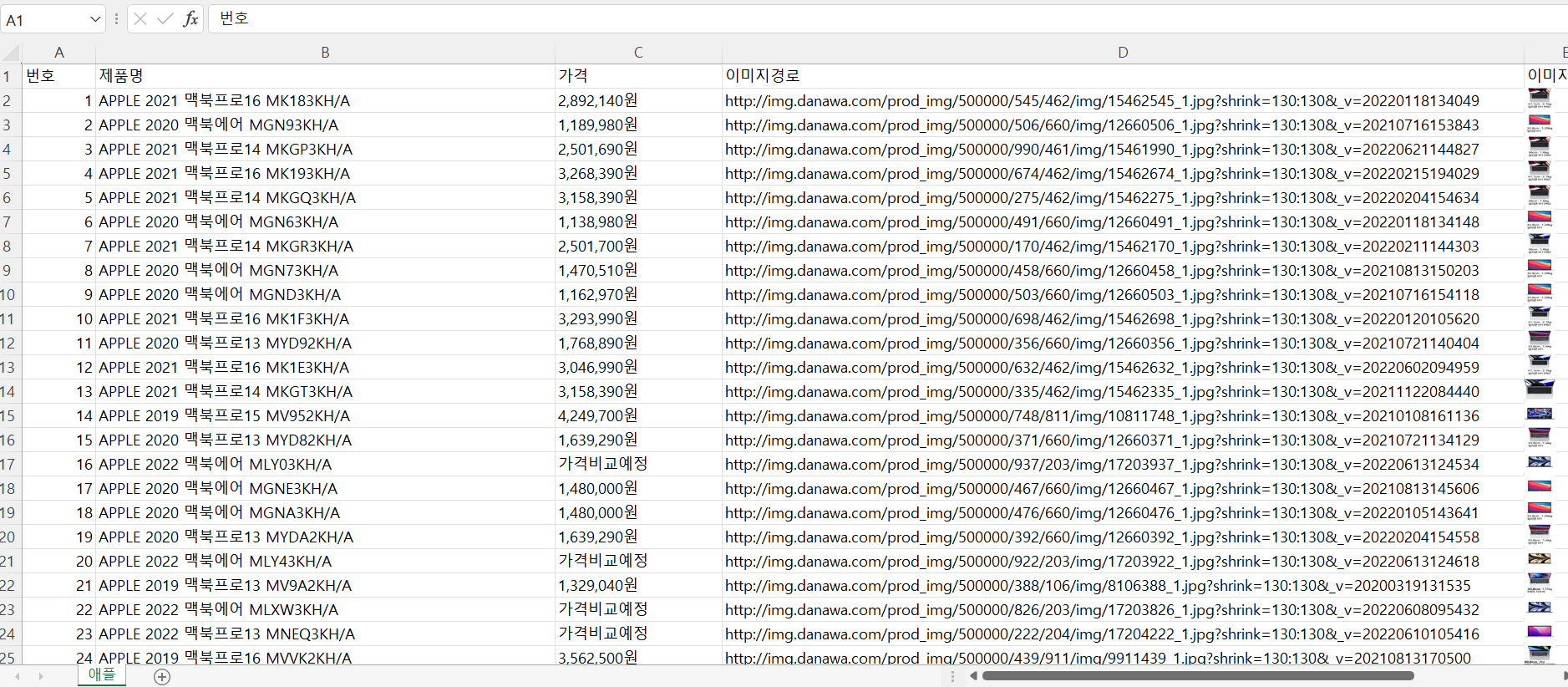
ws.append(["번호", "제품명", "가격", "이미지경로", "이미지"])
browser = webdriver.Chrome()
browser.maximize_window()
time.sleep(1)
# 제조사 더보기 클릭
WebDriverWait(browser, 3).until(
EC.presence_of_element_located(
(By.XPATH, '//*[@id="dlMaker_simple"]/dd/div[2]/button[1]')
)
).click()
# Apple 버튼 클릭
browser.find_element(
By.XPATH, '//*[@id="selectMaker_simple_priceCompare_A"]/li[17]/label'
).click()
# 제품 목록이 화면에 로딩되도록 대기
time.sleep(5)
# 상품 정보 추출 - 상품명, 가격(첫번째), 이미지 src
# 현재 페이지 / 크롤링할 페이지 수 지정
cur_page, target_crawl_num = 1, 6
# 번호 출력
idx = 1
# 페이지 제어 총 6페이지
while cur_page <= target_crawl_num:
# 매번 받아서 파싱
soup = BeautifulSoup(browser.page_source, "lxml")
# 상품 목록 리스트 가져오기
product_list = soup.select(
"div.main_prodlist_list > ul> li:not(.prod_ad_item):not(.product-pot)"
)
print(product_list)
# 현재 페이지 출력
print("=============Current Page : {}".format(cur_page))
# 상품 정보 출력 1페이지당 30개
for product in product_list:
# 제품명
product_name = product.select_one("p > a").text.strip()
# 가격
product_price = product.select_one("p.price_sect > a").text.strip()
# 이미지 경로
product_image = product.select_one(".thumb_image img")
if product_image.get("data-original"):
product_image = product_image.get("data-original")
else:
product_image = product_image.get("src")
if "http:" not in product_image:
product_image = "http:" + product_image
# 엑셀 추가 : 상품정보
ws.append([idx, product_name, product_price, product_image])
idx += 1
# 이미지 다운로드 받아서 엑셀 삽입
res = requests.get(product_image)
img_save = BytesIO(res.content)
img = Image(img_save)
img.width = 30
img.height = 20
ws.add_image(img, "E" + str(idx)) # E2 셀부터 삽입 시작
# for문 종료
print() # 한페이지 끝남.
browser.save_screenshot(
"./RPAbasic/crawl/download/target_page{}.png".format(cur_page)
)
# 현재 페이지 번호 변경
cur_page += 1
if cur_page > target_crawl_num:
print("크롤링 성공")
break
# 다음페이지 클릭
# 페이지 클릭 시
WebDriverWait(browser, 2).until(
EC.presence_of_element_located(
(By.CSS_SELECTOR, "div.number_wrap > a:nth-child({})".format(cur_page))
)
).click()
# soup 삭제
del soup
# 다음 페이지 로딩될 때까지 기다리기
time.sleep(3)
# while문 종료
# 엑셀 저장
wb.save("./RPAbasic/crawl/download/danawa.xlsx")
wb.close()
time.sleep(3)
browser.quit()
RPAbasic\crawl\selenium1 폴더 - 20_bank.py
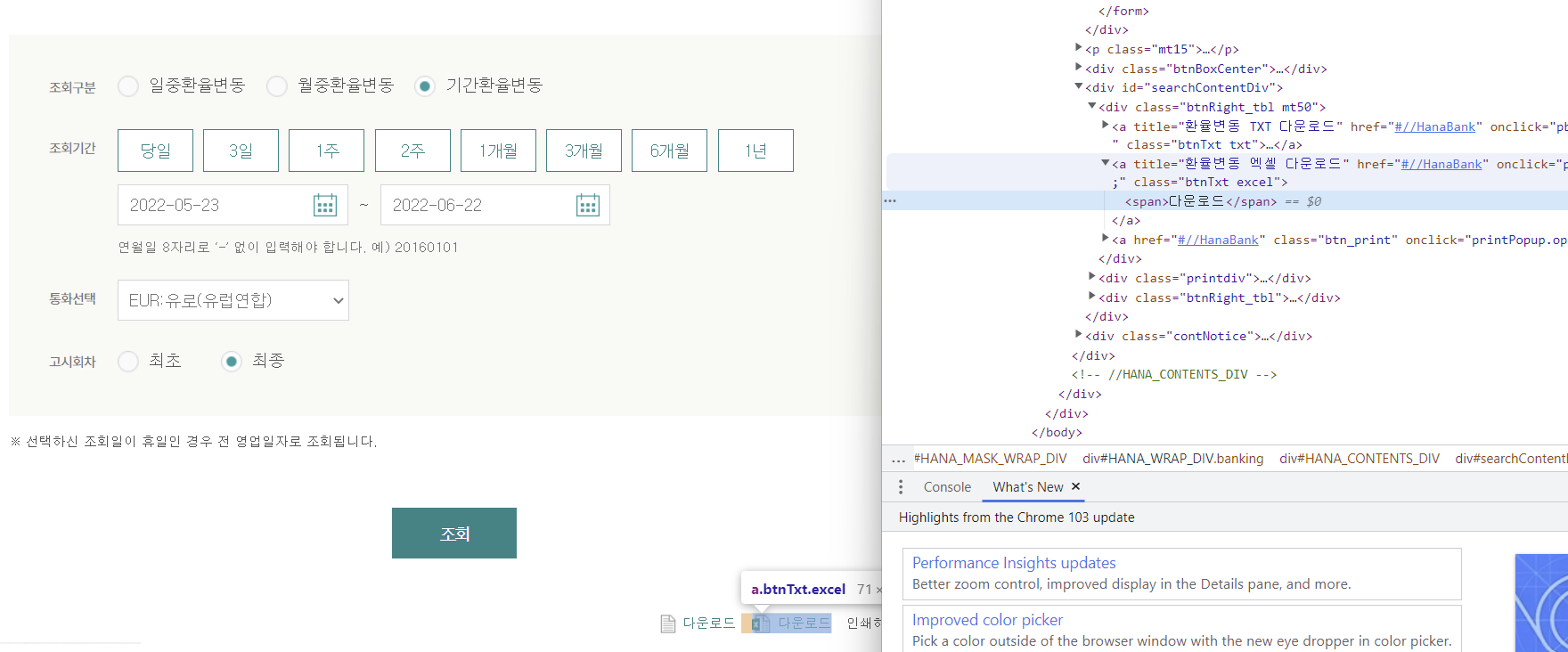
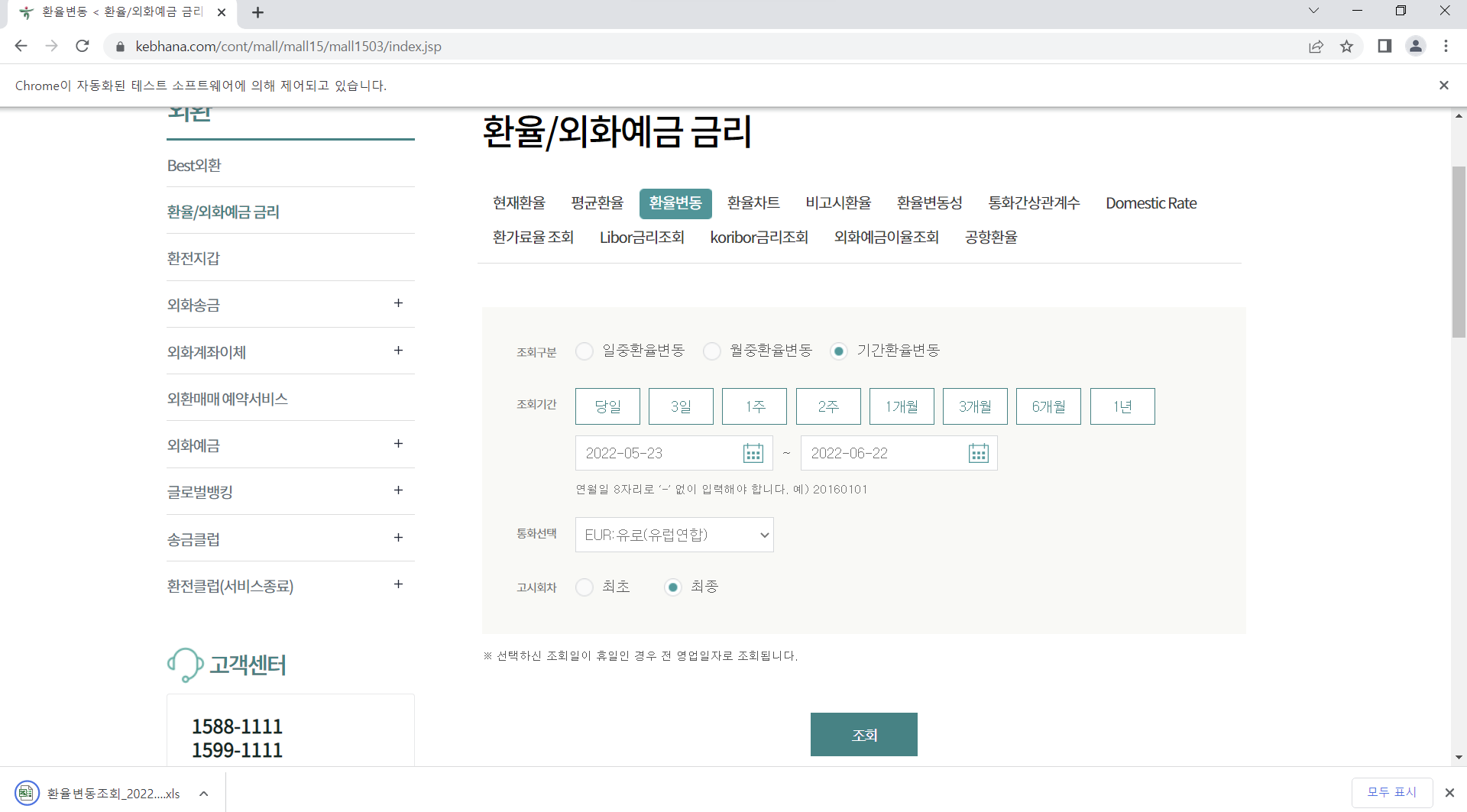
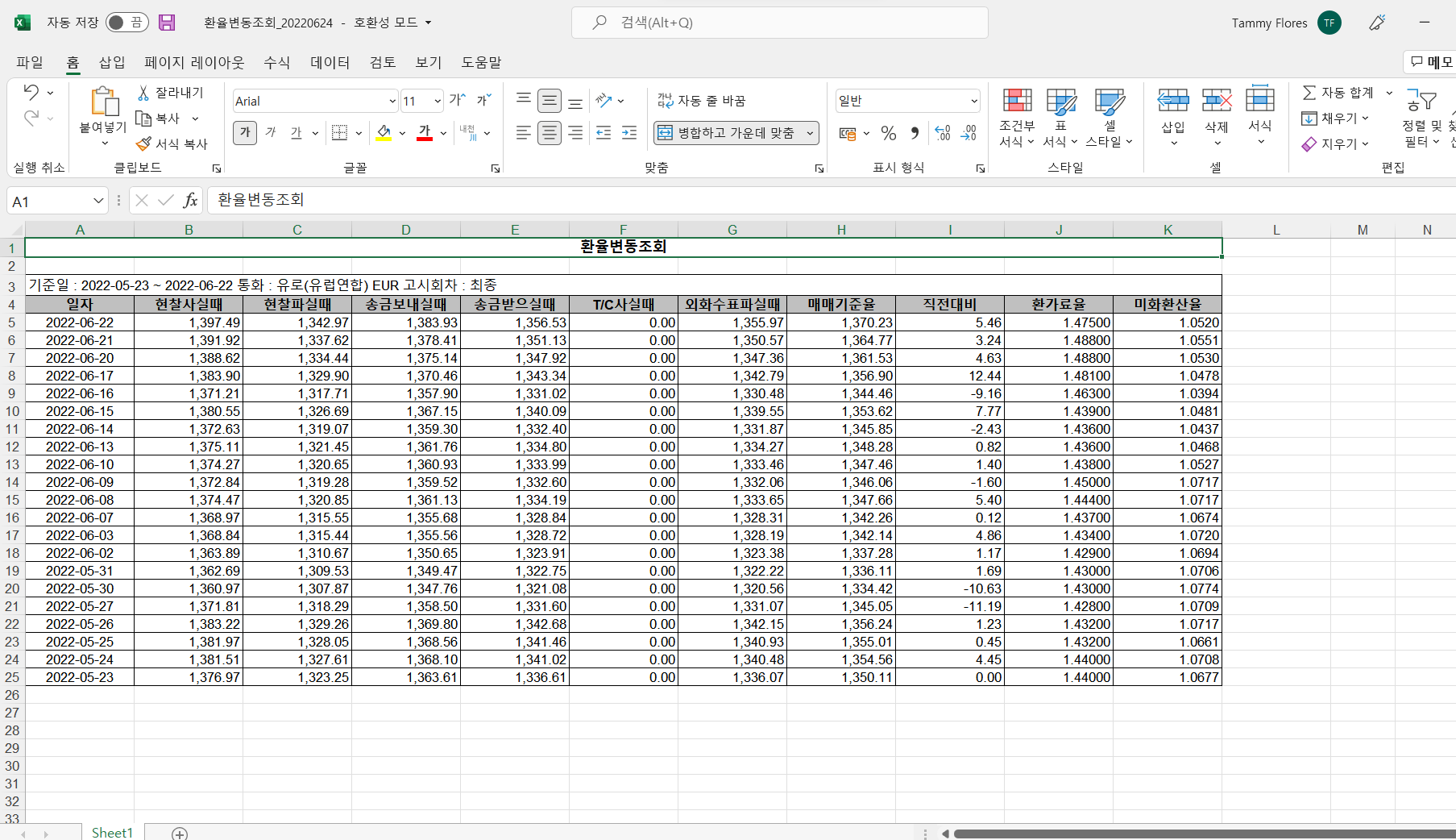
환율변동 - 기간 설정 후 엑셀에 다운
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
browser = webdriver.Chrome()
browser.maximize_window()
# iframe 안으로 들어가기
browser.switch_to.frame("bankIframe")
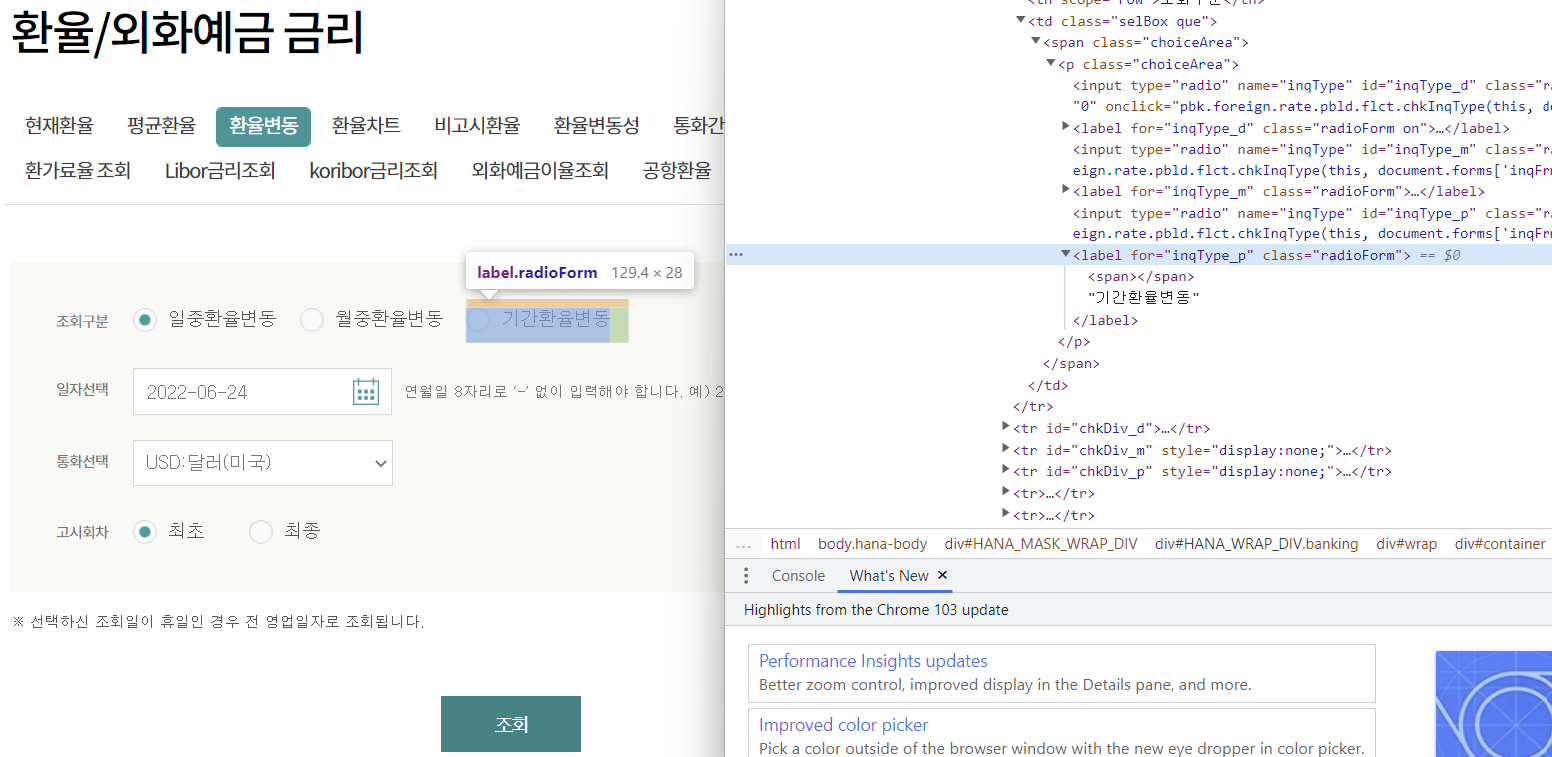
# 기간 환율변동 클릭
browser.find_element(
By.XPATH, '//*[@id="inqFrm"]/table/tbody/tr[1]/td/span/p/label[3]'
).click()
# 시작일자(20220523)
start_date = browser.find_element(By.ID, "tmpInqStrDt_p")
start_date.clear()
start_date.send_keys("20220523")
time.sleep(1)
# 종료일자(20220622)
end_date = browser.find_element(By.ID, "tmpInqEndDt_p")
end_date.clear()
end_date.send_keys("20220622")
time.sleep(1)
# 통화선택 --> 유로 클릭
browser.find_element(By.ID, "curCd").send_keys("EUR:유로(유럽연합)")
# 고시 회차 --> 최종 클릭
browser.find_element(
By.XPATH, '//*[@id="inqFrm"]/table/tbody/tr[6]/td/span/p/label[2]'
).click()
# 조회 버튼 클릭 - iframe안에 있음
browser.find_element(By.XPATH, '//*[@id="HANA_CONTENTS_DIV"]/div[2]/a/span').click()
time.sleep(1)
# 엑셀 다운로드 클릭
browser.find_element(By.XPATH, '//*[@id="searchContentDiv"]/div[1]/a[2]/span').click()
time.sleep(3)
browser.quit()
'Python' 카테고리의 다른 글
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(7) (0) | 2022.10.09 |
|---|---|
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(6) (1) | 2022.10.08 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(4) (0) | 2022.10.06 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(3) (1) | 2022.10.05 |
| Python RPA(업무자동화) 개념 및 실습 - 크롤링(selenium)(2) (0) | 2022.10.04 |
'Python' Related Articles
more




Comments