
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- SQL수업
- sql따라하기
- 파이썬수업
- SQLSCOTT
- python수업
- 수업기록
- sql연습하기
- 주피터노트북맷플롯립
- 주피터노트북판다스
- 파이썬차트
- 파이썬
- 파이썬시각화
- 주피터노트북데이터분석
- 판다스데이터분석
- 데이터분석시각화
- 파이썬데이터분석
- 팀플기록
- python데이터분석
- 주피터노트북그래프
- 주피터노트북
- 판다스그래프
- python알고리즘
- matplotlib
- 파이썬크롤링
- 맷플롯립
- 파이썬데이터분석주피터노트북
- 파이썬알고리즘
- sql연습
- Python
- SQL
- Today
- Total
목록수업기록 (187)
IT_developers
 Python 데이터 분석(주피터노트북) - Pandas(box plot)
Python 데이터 분석(주피터노트북) - Pandas(box plot)
Box plot(상자 ) 백분위 수 : 데이터를 백등분 한 것 사분위 수 : 데이터를 4등분 한 것 중위수 : 데이터의 정 가운데 순위에 해당하는 값.(관측치의 절반은 크거나 같고 나머지 절반은 작거나 같다.) 제 3사분위 수 (Q3) : 중앙값 기준으로 상위 50% 중의 중앙값, 전체 데이터 중 상위 25%에 해당하는 값 제 1사분위 수 (Q1) : 중앙값 기준으로 하위 50% 중의 중앙값, 전체 데이터 중 하위 25%에 해당하는 값 사분위 범위 수(IQR) : 데이터의 중간 50% (Q3 - Q1) 기본 라이브러리 import pandas as pd import matplotlib.pyplot as plt import numpy as np 한글처리 plt.rcParams['font.family'] =..
 Python 데이터 분석(주피터노트북) - Pandas(histogram)
Python 데이터 분석(주피터노트북) - Pandas(histogram)
기본 라이브러리 import pandas as pd import matplotlib.pyplot as plt import numpy as np 한글처리 plt.rcParams['font.family'] = 'Malgun Gothic' plt.rcParams['axes.unicode_minus'] = False 1~100까지 랜덤 50개 숫자 데이터 생성 1) 기본 히스토그램 hist() kind='hist' 기본 구간 10 bins : 구간 변경 1000개 데이터 생성 2) 히스토그램 옵션 주기 alpha : 투명도 bins : 구간 stacked : 쌓기 orientation='horizontal' :옆으로 그리기 데이터 생성 3) 그룹별 히스토그램 카테고리가 구현 되어 있을 때 알아서 그려짐. plo..
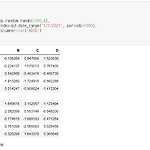 Python 데이터 분석(주피터노트북) - Pandas(bar plot)
Python 데이터 분석(주피터노트북) - Pandas(bar plot)
기본 라이브러리 import pandas as pd import matplotlib.pyplot as plt import numpy as np 한글처리 plt.rcParams['font.family'] = 'Malgun Gothic' plt.rcParams['axes.unicode_minus'] = False 날짜 데이터 1000개 생성 1) 기본 막대 차트 2021-01-05 날짜로 차트 작성 kind='bar' : 종류를 지정 plot.bar() 2) 가로 축 선 생성 axhline (): 가로 축 음수가 있을 때 기준 = 0 옵션 : rot = 0 10개의 데이터 3) 누적 막대 stacked = True 4) 수평 막대 barh kind = 'barh' 5) 인덱스 설정 group, sector ..
 Python 데이터 분석(주피터노트북) - Pandas(plot)
Python 데이터 분석(주피터노트북) - Pandas(plot)
기본 라이브러리 import pandas as pd import matplotlib.pyplot as plt import numpy as np 한글처리 plt.rcParams['font.family'] = 'Malgun Gothic' plt.rcParams['axes.unicode_minus'] = False 1) 기본 선 그래프 범례 기본 2) 범례 제거 3) 보조 축 설정 secondary_y : 보조축 4) 보조축 + 축 레이블 지정 set_ylabel : 축 레이블 지정 mark_right = False 5) subplots 각각 나눠서 그려줌 동일한 차트로 그려냄 layout sharex : x 축 공유 sharey : y축 공유 subtitle : 전체 피겨의 타이틀
 Python 데이터 분석(주피터노트북) - 유튜브 랭킹 크롤링 및 데이터 분석
Python 데이터 분석(주피터노트북) - 유튜브 랭킹 크롤링 및 데이터 분석
유튜브 랭킹 크롤링 url : https://youtube-rank.com/board/bbs/board.php?bo_table=youtube&page=1 1 ~ 10 페이지 크롤링 카테고리명, 채널명, 구독자수, view 수, 동영상 개수 추출 추출된 정보는 엑셀 저장 selenium + soup 사용 1. 라이브러리 import pandas as pd import matplotlib.pyplot as plt from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from bs4 import BeautifulSoup import t..
 Python 데이터 분석(주피터노트북) - 음악 순위 크롤링 및 데이터 분석
Python 데이터 분석(주피터노트북) - 음악 순위 크롤링 및 데이터 분석
멜론, 벅스, 지니 음악 순위 크롤링 각 음악 사이트의 크롤링 정보를 엑셀 저장 저장된 정보를 읽어온 후 3개의 데이터 합치기 TOP 100 - 순위, 노래제목, 가수이름 기본 설정 Selenium from selenium import webdriver from selenium.webdriver.common.by import By BeautifulSoup from bs4 import BeautifulSoup Pandas import pandas as pd import requests import time 1. 멜론 TOP100 음악 정보 가져오기 1) url 2) 전체 데이터 확인 3) 크롤링 결과 확인 및 엑셀 저장 서비스 : 멜론 순위, 타이틀, 가수 순으로 저장 2. 벅스TOP100 음악 정보 가져..
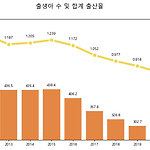 Python 데이터 분석(주피터노트북) - 합계 출산율 데이터 분석
Python 데이터 분석(주피터노트북) - 합계 출산율 데이터 분석
탐색적 데이터 분석 데이터 분석이라는 것이 특별히 정해진 규칙은 없음 기본적 작업 데이터 출처와 주제에 대한 이해 데이터 구성요소, 속성 확인 평균, 중앙값... 통계 요약 정보 출생아 수 합계 출산율 데이터 분석 https://www.index.go.kr/potal/main/EachDtlPageDetail.do?idx_cd=1428 엑셀 다운로드 (경로 : data/dataset) 저장된 파일 확인 1. 기본 설정 2. 데이터 로드 3. 데이터 정리 4. 데이터 전처리 5. 정리된 데이터 확인 6. 시각화 1) 행/열 변경 df.T df.transpose() 2) 선 그래프 3) 오른쪽 축 설정 excel에서의 z축 4) 출생아수 - 막대, 합계 출산율 - 라인 5) 그래프 디자인
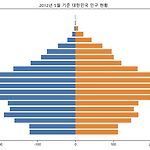 Python 데이터 분석(주피터노트북) - 인구현황 데이터 분석
Python 데이터 분석(주피터노트북) - 인구현황 데이터 분석
탐색적 데이터 분석 데이터 분석이라는 것이 특별히 정해진 규칙은 없음 기본적 작업 데이터 출처와 주제에 대한 이해 데이터 구성요소, 속성 확인 평균, 중앙값... 통계 요약 정보 행정 안전부에서 2012년 2022년 데이터를 다운로드 후 데이터 분석 data_analytics -> project -> 인구현황 연령별 인구 현황.ipynb 10년 전 인구 변화 엑셀 다운로드 data_analytics -> data -> dataset 저장 201205_201205_연령별인구현황_월간.xlsx 데이터 기본 정보 확인 남자와 여자 컬럼명 불일치 데이터 전처리 : 데이터 수정 에러 문구 ValueError: cannot convert float NaN to integer 피라미드 차트 그리기 라이브러리 한글처리..